A fairly important aspect of retail software is inventory management. Often this requires some kind of counter that reduces the count of stock items based on the number of orders placed. This poses a particularly difficult challenge in relational databases because we need to ensure consistency. Think of a product table which has a stock count in the table. We need to reduce the count by one every time an order is placed for that product. As you can imagine this will cause significant locking and blocking on the product table due to exclusive locks that are placed whenever we want to decrement the count by 1. In this post be explore a couple of different methods that you could use to implement this functionality and then evaluate the performance implications of each choice.
Let s start by creating the base tables.
CREATE TABLE [dbo].[Products_disk] (
[productid] [int] NOT NULL
,[productcount] [int] NULL
) ON [PRIMARY]Create the table Orders_disk
CREATE TABLE [dbo].[Orders_disk] (
[orderid] [int] IDENTITY(1, 1) NOT NULL
,[Productid] [int] NULL
,[orderdate] [datetime] NULL
) ON [PRIMARY]
GONext we insert some dummy products into the Products table and use a procedure to randomly pick a product and insert some data into the orders table.
DELETE
FROM Products_disk
GO
INSERT INTO Products_disk (
productid
,productcount
)
SELECT 0
,10000
UNION ALL
SELECT 1
,10000
UNION ALL
SELECT 2
,10000
UNION ALL
SELECT 3
,10000
GO
SELECT *
FROM Products_diskNext we have our order create procedure which will randomly generate orders for our 4 products.
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE PROCEDURE [dbo].[placeorder]
AS
declare @productid int =CAST(ROUND(rand()*10,0) as int) %4
IF (
SELECT productcount
FROM products_disk
WHERE Productid = @productid
) > 0
BEGIN
INSERT INTO Orders_disk
(
Productid
,orderdate
)
SELECT @productid
, GETDATE()
UPDATE products_disk
SET productcount = productcount - 1
WHERE productid = @productid
END
GO
DISK BASED TABLES
As you can see in the above procedure we check if productCount is > 0 then insert into Orders_disk table and follow that up by updating the Product_disk table. Using the SQLQUeryStress tool we simulate 200 connections executing the query 10 times for a total of 2000 executions. This procedure averages out at 4.2 to 4.3 ms as shown below.
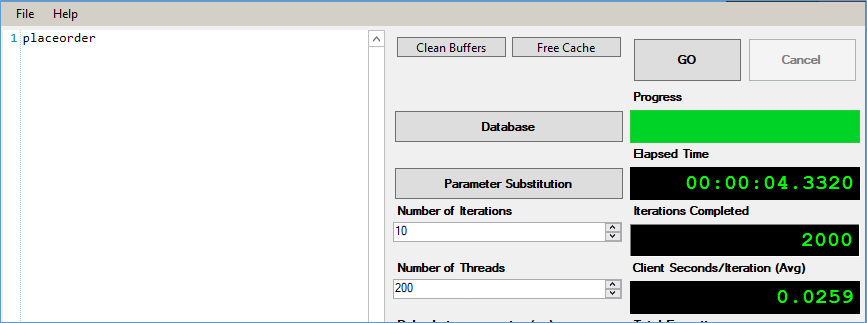
It is worthwhile noting in this case we didn’t have any indexes on either table, next in order to simulate a more real life scenario lets add indexes and simulate for a 1000 products.
INSERT INTO Products_disk
SELECT max(productid) + 1,
10000
FROM Products_disk
GO 996
Adding the additional products seem to have increased the execution time by a few ms to 4.8ms avg. Time for some indexes
CREATE CLUSTERED INDEX [CIX_ProductIX] ON [dbo].[Products_disk]
(
[productid] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON,
OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF)There really is no point in adding an index on Order table at the moment since it doesn’t really have any selects happening on it. The procedure has been modified to MOD 1000. As expected the index didn’t really improve performance by much owing to the small size of the table.
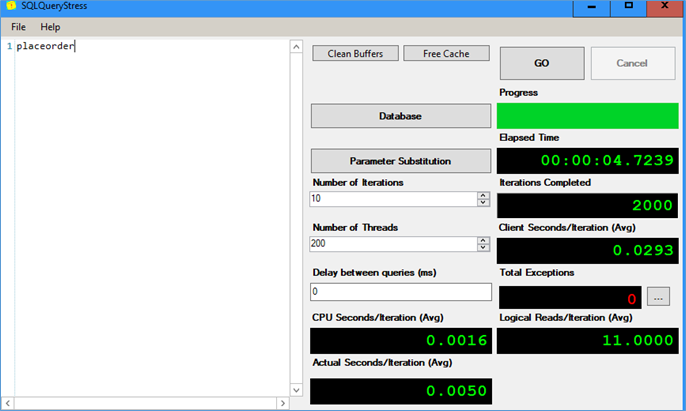
Now let us explore the same scenario using an in memory table, considering the highly transactional nature of the operations we assume the in memory tables will result in significant performance gains.
IN MEMORY TABLES
As before we start by creating in memory tables.
Product Table below
CREATE TABLE [dbo].[products]
(
[productid] [int] NOT NULL,
[productcount] [int] NULL,
INDEX [IX_Productid] NONCLUSTERED
(
[productid] ASC
),
CONSTRAINT [products_primaryKey] PRIMARY KEY NONCLUSTERED HASH
(
Productid
)WITH ( BUCKET_COUNT = 1000) )WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA )
GOOrders table below
CREATE TABLE [dbo].[Orders] (
[orderid] [int] IDENTITY(1, 1) NOT NULL
,[Productid] [int] NULL
,[orderdate] [datetime] NULL
,CONSTRAINT [Orders_primaryKey] PRIMARY KEY NONCLUSTERED HASH ([orderid]) WITH (BUCKET_COUNT = 131072)
)
WITH (
MEMORY_OPTIMIZED = ON
,DURABILITY = SCHEMA_AND_DATA
) GONext we create a natively compiled procedure to load the data into the in memory tables
CREATE PROCEDURE dbo.placeinmemorder
WITH NATIVE_COMPILATION
,SCHEMABINDING
AS
BEGIN
ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT
,LANGUAGE = N'us_english'
)
--Insert statements for the stored procedure here
DECLARE @productid INT = CAST(ROUND(rand() * 10, 0) AS INT) % 1000
BEGIN
INSERT INTO dbo.Orders (
Productid
,orderdate
)
SELECT @productid
,GETDATE()
FROM dbo.products
WHERE Productid = @productid
AND ProductCount > 0
UPDATE dbo.products
SET productcount = productcount - 1
WHERE productid = @productid
END
END
GO
After executing the procedure as before using the SQLQueryStress tool. We notice a slight improvement IN execution times as displayed below: –
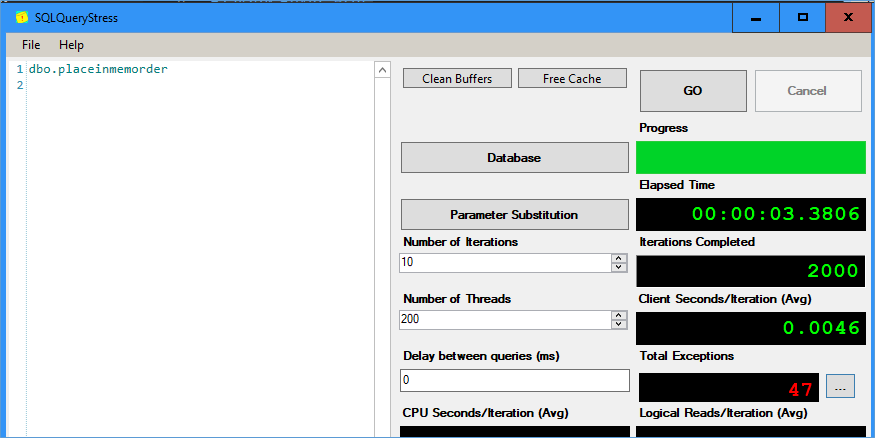
But this comes at the cost of writer block writer conflicts ( 47 errors) . To avoid this issue let’s try and avoid updating the table at all. This would require us to rewrite the query as below
ALTER PROCEDURE dbo.placeinmemorder
WITH
NATIVE_COMPILATION,
SCHEMABINDING
AS BEGIN ATOMIC WITH
(
TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english'
)
--Insert statements for the stored procedure here
declare @productid int =CAST(ROUND(rand()*10,0) as int) %1000
BEGIN
INSERT INTO dbo.Orders (
Productid
,orderdate
)
SELECT @productid
,GETDATE()
FROM dbo.products
WHERE Productid = @productid
and ProductCount - (select count(*) from dbo.orders where productid =@productid)>0
END
END
GOThis approach worked fine as long as the number of rows in the order table was small. But it degrades rapidly as the size of the table increases. e.g its avg about 4sec/2000 rows with 87K rows in orders table. It is pretty clear from this that using a shared lock approach doesn’t suit this particular requirement. While it does avoid the use on one exclusive lock it does cause an issue in the way that hundreds or thousands of shared locks need to be acquired instead.
Considering that In memory tables offer speed by compromising the user experience we can put this approach on Hold for the moment while we explore other Disk based options in the next part.
More information
Please consider subscribing !
