When it comes to using Always On in Microsoft SQL Server it is a technology that has been around for a long time. The feature was introduced in MSSQL 2012 and at that time it was primarily limited to on-premise installations of Microsoft SQL Server. Since then, this feature has also been made the default mechanism for high availability inside Microsoft Azure SQL Database Solutions. One of the key advantages of using Always On is its ability to use readable secondary databases. While the primary accepts both read and write connections the secondary will be able to process read connections and therefore is often used for reporting and other high latency related data retrieval. It is also a great feature to use when you have multiple instances that are secondary so that you have offsite disaster recovery capabilities as well.
One of the big reasons why you should be using Always On and Microsoft Azure SQL database Cloud is because Microsoft has a service level agreement that needs to be maintained on their end and therefore every database that is created in Microsoft Azure Cloud automatically has 2 internal replicas. One replica (Internal Replica A) is stored within the same data centre to provide immediate failover in the event of localised failures such as a loss of power and network connectivity within one floor of same data centre. Another replica (Internal Replica B) is available for those instances where you need a disaster recovery scenario and therefore this particular replica is usually stored in data centre sufficiently far away so as not to be impacted by geographical issues such as earthquakes etc. Both of these replicas can be made available as secondary read only replicas if needed within the Azure portal provided you have a premium service tier or higher.
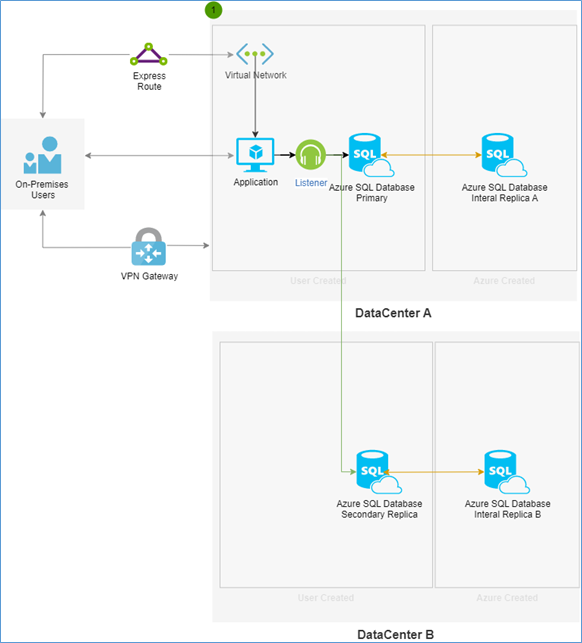 A good way to save money when using Microsoft SQL Azure is create an active geo replication failover replica in a remote location (Data centre B). For a critical production database this is something that you would normally do anyway. When set up is should look similar to the diagram below you should have up to four instances that are immediately available for read if you are using a premium service tier. The options available to you are the primary which is in data centre A and its internal replica A available because of the Microsoft SLA. In addition to this if you have created a secondary readable replica, you will automatically have a secondary readable replica in data centre B. As well as its standby internal server also located in Data centre B.
A good way to save money when using Microsoft SQL Azure is create an active geo replication failover replica in a remote location (Data centre B). For a critical production database this is something that you would normally do anyway. When set up is should look similar to the diagram below you should have up to four instances that are immediately available for read if you are using a premium service tier. The options available to you are the primary which is in data centre A and its internal replica A available because of the Microsoft SLA. In addition to this if you have created a secondary readable replica, you will automatically have a secondary readable replica in data centre B. As well as its standby internal server also located in Data centre B.
It is important to understand that the limitations of the listener still apply even in this case where the listener is only going to detect the primary and the secondary within data centre A and data centre B ( green arrow in the below diagram) it will not be able to detect the internal replicas that is hosted by Microsoft in data centre A and B if you need to connect to these instances you will still need to hardcode the server name and set read intent only at which point the routing internally redirects the connection ( Orange arrow) to the internal server and not to the standby replica.
By leveraging this capability, you actually end up with four servers but you only pay the price for two. In a production environment that is highly scalable with large number of transactions you will be able to process multiple requests by leveraging or distributing the workload across four servers. This is a feature that needs to be tested out thoroughly. Depending on your workload it may or may not benefit you an example would be where the OLTP system primarily focuses on inserts rather than reads. In this case having three additional replicas for read doesn’t really make much sense because the majority of the utilisation is actually happening on the primary server. However if you are able to offload read load to other servers then you could potentially scale down the service tier of the primary since a lot of the workload will be offloaded to secondary instances. Keep in mind when this happens you also need to provision a little extra buffer because in the event of failover all the workload is suddenly showing up on the data centre B secondary replica and if you are using a DTU based pricing model there is a good chance that you will actually run out of DTUs. This would result in a whole other type of downtime which would require you to scale up the secondary replica to handle the additional workload. Unfortunately as you may be aware in Microsoft Azure SQL when you need to scale up the scale up time is basically proportional to the size of the database and this means that a large database would potentially require a significantly large amount of time in order to failover.
Another option that is available to you is also to go ahead and use a managed instance and configure in data sync or a red replica to a virtual machine this is a good way to go ahead and distribute workloads with virtual machines and reduce such storage cost even further however this option is not available with the dtu based model and therefore is only available as a managed instance where you have full control and can go ahead and configure the options required to set up always on failover to a virtual machine. Tell me more about this topic in a later blog for now we’re talking mainly about elastic waste model.