Starting today we are introducing a new type of blog content which covers questions from #sqlhelp. We pick random questions from the feed and try to cover them in detail, while trying to explore other options or scenarios that might not be so obvious.
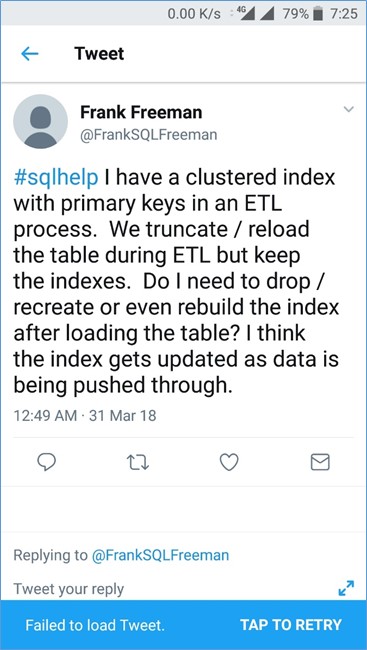
The Questions is should you remove the index before doing ETL? Some points to keep in mind here are:-
- There is a PK which might indicate a clustered index.
- They are doing ETL so we can reasonably expect at least 100K rows per batch.
- There is no mention of Bulk insert or the way the ETL is being performed.
- Would truncating the table and loading the data affect the speed of the ETL compared to say delete and load?
- Does the index need to be rebuilt.
Because we don’t know the type of tool being used to perform ETL we will simply explore the speed of the operation wrt. DB here. To start off I have a table called OntimeEtl which contains 509519 rows. We will move the data from this table in the Madworks database to another table in the ETL database under different scenarios to measure the load times.
The ETL database is in Full recovery model and has an initial size of 500MB so that auto growth etc. doesn’t impact the load times. First we load into a heap table with no index and only an identity column added which can be used later for PK tests. Below are the results of the test. As you can see regardless of the nature of the underlying Disk a non-indexed scenario always performs faster than a table with an index. More interestingly we see that using a NON Clustered Unique Index is a better choice than using the default Clustered index that gets created with a PK. The below table is ordered best to worst from left to right.
Run | SSD No Index | SSD NCIX | SSD Clus Index | HDD No Index | HDD Clus Index |
1 | 9586 | 10580 | 13334 | 14730 | 22717 |
2 | 8937 | 11150 | 15013 | 15220 | 20793 |
3 | 9700 | 11107 | 13060 | 15090 | 20560 |
4 | 9923 | 10417 | 12244 | 15253 | 19613 |
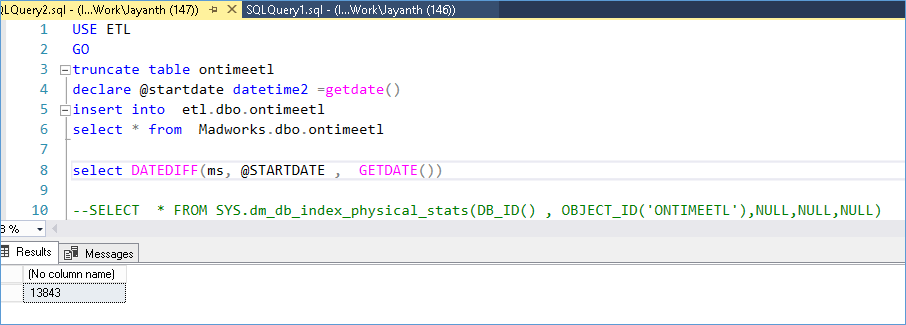
5 | 8844 | 10466 | 13843 | 16390 | 23610 |
So now that it’s clear we should drop the index to improve the ETL performance the question of rebuild doesn’t arise. But let’s assume we decided to keep the index anyway, the next question would be should we rebuild the index?
Below are the index physical stats for the clustered index when we use the recordid column as the PK and it’s of data type int and the input data is an identity column.

Below is the index stats for when the recordid column data type is changed to varchar(10)
![]()
In either case we see that after we insert data into the table the clustered index isn’t really fragmented. This is true even if the incoming data is arriving in random order. We can see that an ordered column value like identify column results in more pages per fragment which is generally better for scans. Whereas if we store the data in varchar (10) as shown below

Fewer pages are stored per fragment as a result of page splits. Which is evident from the slightly higher number of pages in the second scenario where we store the data as text. So now it’s clear that even if we did leave the index in place we don’t need to rebuild them after the ETL. Note that rebuilding the clustered index will result in rebuild of non-clustered indexes as well.
So to summarize:-Drop the index of the table when performing ETL operations this will result in the table being loaded faster and then by adding the index later you will have an index with fewer page splits and lesser fragmentation.
Please Consider Subscribing
