A function that might prove useful when querying very large datasets, it provides a count of distinct values for any column in the database except text,ntext , image data types. Why would this be useful? In many cases we see that an approximate count of the rows is sufficient and we don’t really need an exact count. However the default behavior is to provide exact counts mostly because of the C in ACID. So as its name suggests it provides an approximate count of the distinct values so it raises some questions which I have listed below and tried to answer
How to use it?
Using the function is fairly straightforward as shown below
SELECT APPROX_COUNT_DISTINCT(tailnum)
FROM [dbo].[counts]How Approximate is it?
In this case the query is executed against a table with 979265 rows. The result is
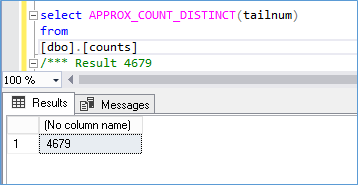
The actual row count is
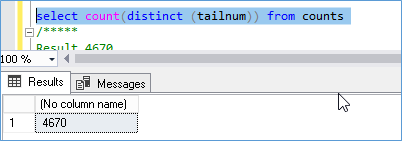
So we see it’s off by 9 rows. Which I guess it not bad.
Let’s try something more unique
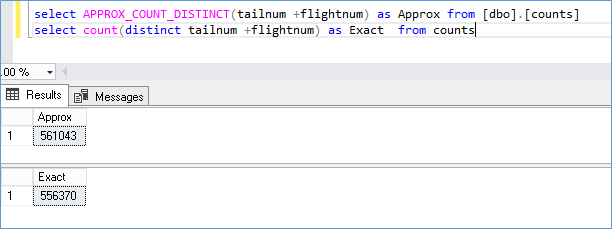
The Approx_count_distinct looked like it was always estimating on the higher side but that doesn’t seem to be the case as can be seen here
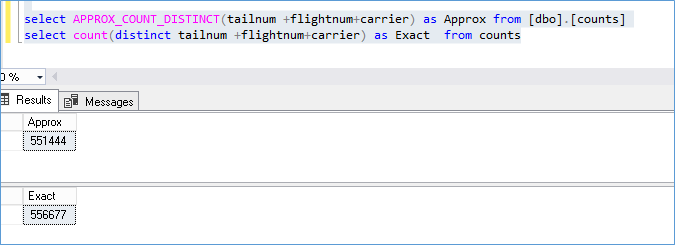
In each case I was able to calculate the error at less than 1.1% but the official documentation suggests 2%
Is it faster than a Normal Count Distinct?
It is hard to say if it will always give better performance because for most runs they seem neck and neck e.g. let’s examine the performance where we start off with a cold cache (no data in memory)
Notice the Read ahead reads, which indicate some kind of disk activity going on in the background
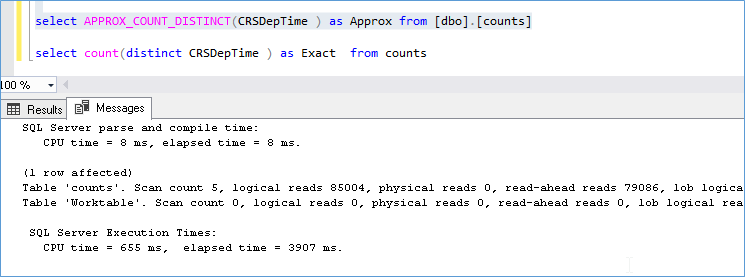
With a warm cache we see that the query is much faster but is heavier on the CPU.
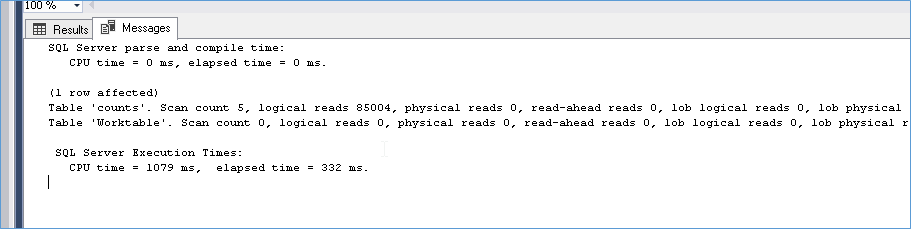
Now let’s try the same with a Count Distinct Query with cold cache
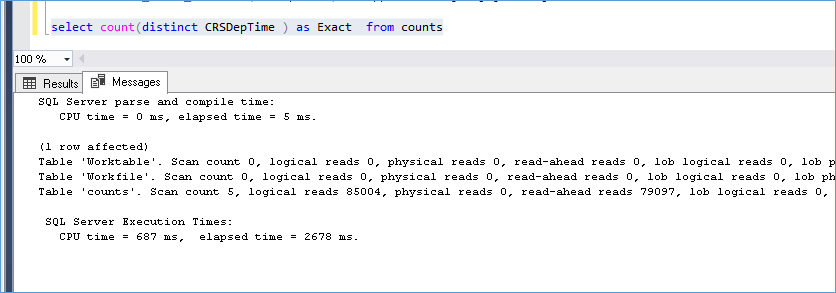
Here again we see that there are read ahead happening which is to be expected. There are no indexes on the columns being queried and we see that performance wise we see the count distinct is both accurate and faster. Let’s see what happens in a warm cache
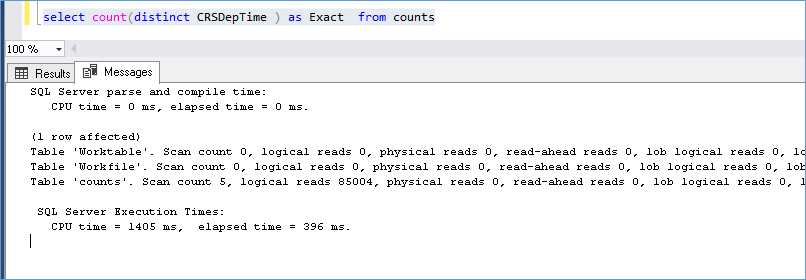
A warm cache execute just as fast as an Approx_count_distnct but we see its slight more heavy on the CPU comparatively. A look at the execution plan shows that while the count distinct does more operations there isn’t much to separate them in terms of overall Cost.
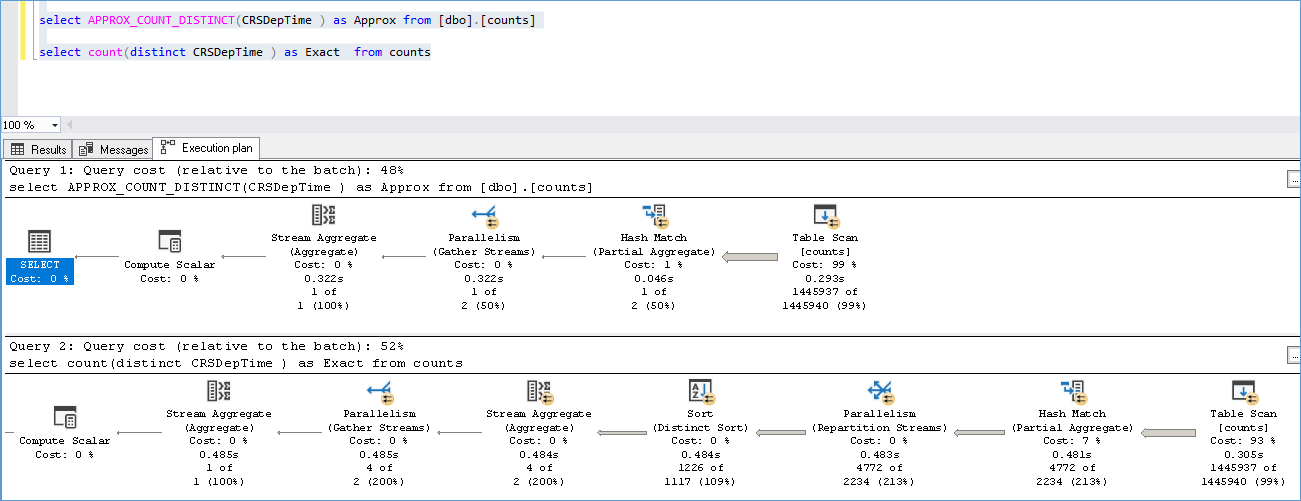
From where does it get its number?
I figured it was fast because it used the statistics so I tried an experiment, notice the counts below, the value for the Approx_count_distinct is 611.
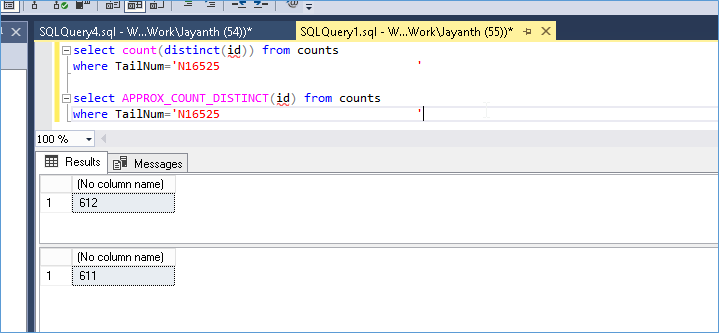
We see that the statistics show the number as 612 not 611. So I figured the stats isn’t what is used to perform this operation.
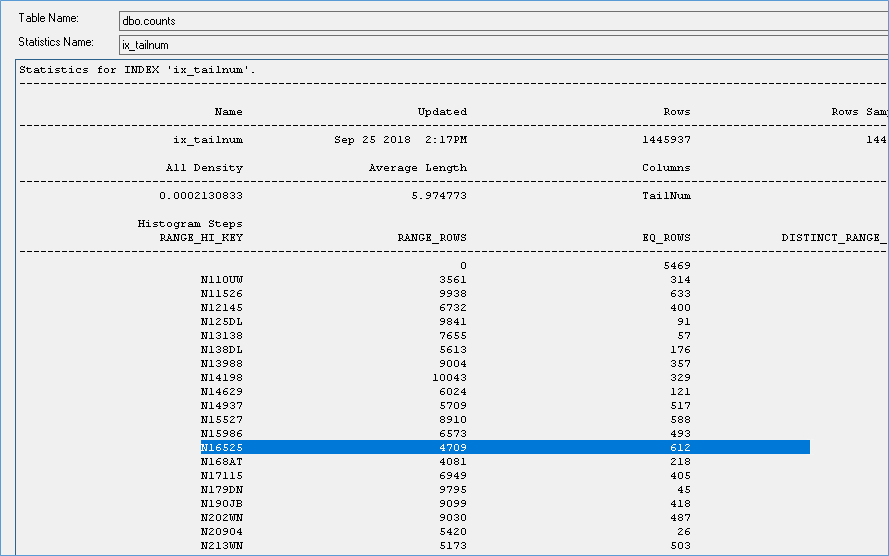
Next I updated 500K records to the above value and disabled auto update stats. In spite of the stats not being updated I see that the counts are reflecting the actual current state and not values shown from the stats.
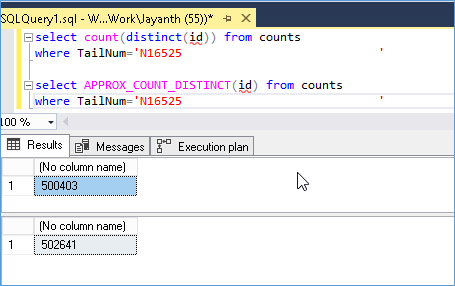
So at this moment I don’t have an answer for where it gets its numbers from but it doesn’t seem like it is coming from the stats that have already been calculated. If it is calculating the number on the fly I expect the IO performance to get worse as we query larger sets of data.
I tried updating a bunch of rows in the table to simulate a locking blocking scenario to see if the APPROX_COUNT_DISTNCT is affected by lock on the underlying data pages and it is. Which is to be expected considering the read ahead reads we saw earlier. In summary there is a disk level component to the way it works, what exactly I don’t know. Yet!!
Is there a way it can be confused?
I had tried to disable auto update stats and delete/Update records from the table but it was still able to provide fairly reasonable counts. So I assume it isn’t using prebuilt statistics to arrive at the numbers. Adding an index didn’t improve the approx_count_distinct value either. Creating the index did result in an Index scan so I have to assume the index is being read in some way.
Should I use it for a KPI or a Average calculation?
I would not use it for a KPI or any other calculations because of discrete values KPIs might end up showing Green when it is actually Yellow or vice versa and due to the inherent error in the number I would also not use it for any further calculations because the errors will add up with each step and the final result might be way of mark.
Please Consider Subscribing
