I recently came across a post in Linkedin about a script that performs Pattern Matching or “Fuzzy Lookup” within TSQL. The Script was definitely an elegant solution to scoring similar words but it still wasn’t exactly Fuzzy Lookup it was pattern matching. Before we continue I guess it will be better to first explain the difference between the terms:-
Pattern Matching simply looks for a particular string within another string. Like search for Jaya in the Name Jayant typically written in T-SQL it would be a LIKE conditions listed as below:-
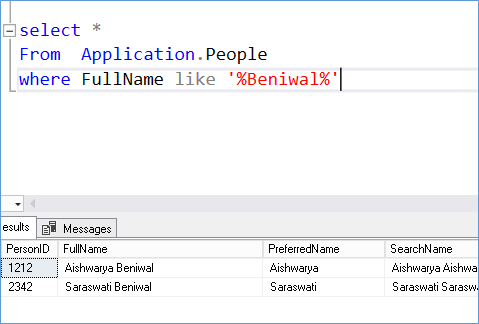
The pattern matching works well only under two criteria
- Pattern is sufficiently long in order to be selective
- The lookup is an exact match for the pattern
Primarily due to the second criteria it fails as a fuzzy lookup search. As demonstrated below:-
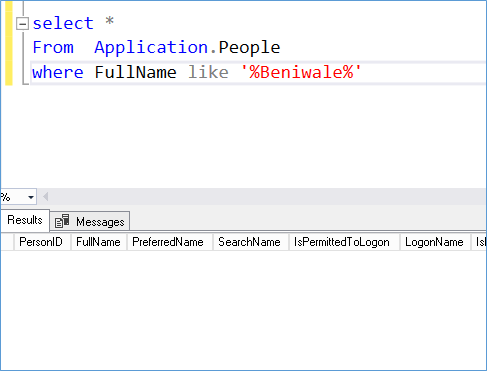
Added an extra e at the end of the word
In order to bypass the precision required for LIKE statement we could explore the SOUNDEX and DIFFERENCE command in TSQL which will help search for strings that sound similar. However the accuracy of the match leaves much to be desired. As you can see from the below screenshot the DIFFERENCE Command provides a score for how similar the words are but the values are between 0 and 4 (4 being the highest).This results in a lack of fidelity. Not to mention the dependence that the search pattern should be the first letter for the search string. In other words searching for Jayanth
in Jayanth J Kurup will work but searching for Kurup in Jayanth J Kurup will not. So we have two problems with using Difference:-
- First LETTER match dependence – Only works if the word we are looking for shows up in the beginning of the string
- Low Fidelity – Even words that are not similar end up in the results
SOLVING PROBLEM 1
We can solve the first problem by simply splitting the strings as shown below and then performing a match, as you can see Beniwal shows up even though I typed in Beniwale (this would not work with like conditions)
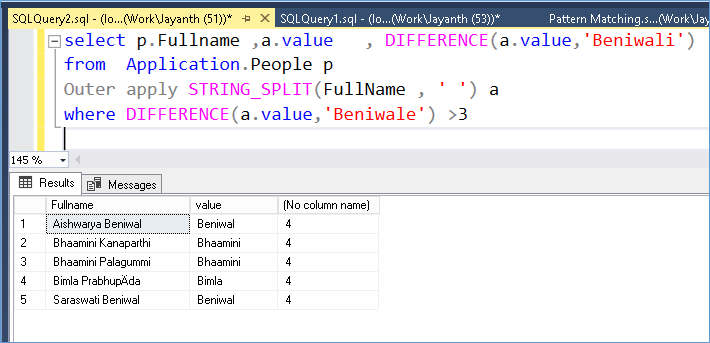
SOLVING PROBLEM 2
In order to increase the fidelity we can simply rely on the dependence of the first letter again. By ignoring the first letter and running DIFFERENCE again we increase the chances of finding words that are similar for both the first and second letter and so on depending on how much accuracy we want. Look at the screenshot below and compare it with the one above. In the above screenshot we see that Bimla and Bhaamini also show up in the output but after ignoring the first letter these words no longer sound anything like Beniwal and therefore their score dips in the second round of running DIFFERENCE.
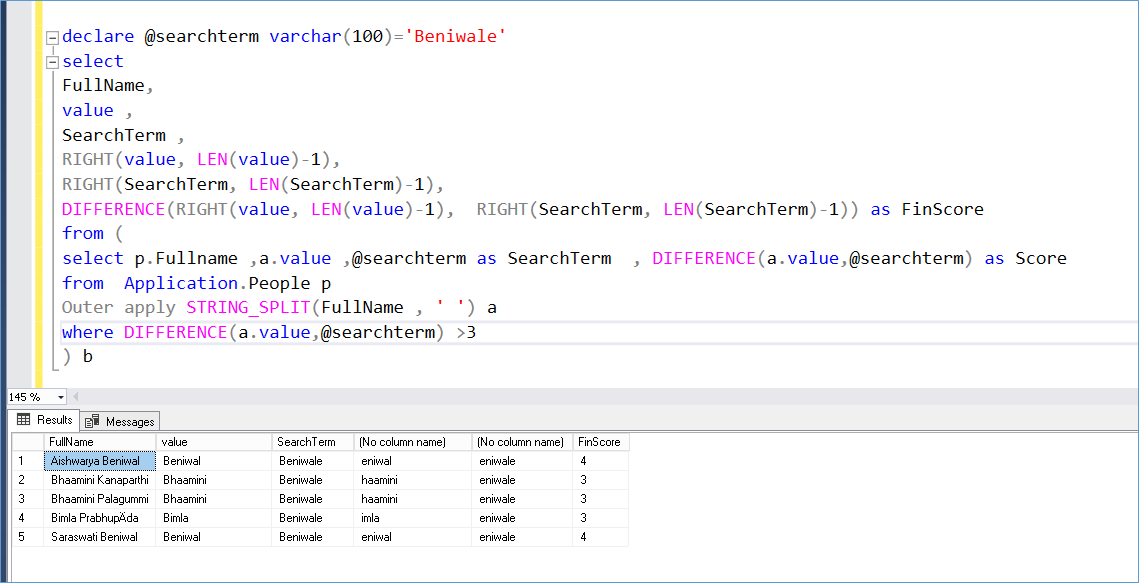
MORE EXAMPLES
For clarities sake I have added a few more examples below
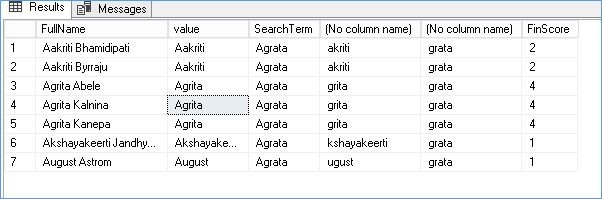
Search term: – Agrata
Actual value: – Agrita
Output
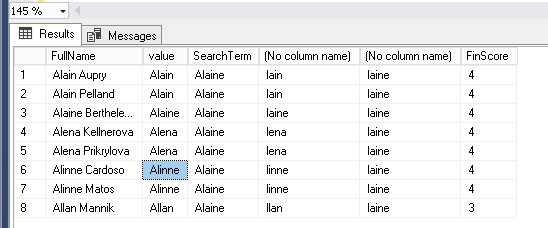
Search term: – Alaine
Actual values: – Alain, Alaina, Alena, Alinne
Output
DECLARE @searchterm VARCHAR(100) = 'Alaine'
SELECT FullName
,value
,SearchTerm
,RIGHT(value, LEN(value) - 1)
,RIGHT(SearchTerm, LEN(SearchTerm) - 1)
,DIFFERENCE(RIGHT(value, LEN(value) - 1), RIGHT(SearchTerm, LEN(SearchTerm) - 1)) AS FinScore
FROM (
SELECT p.Fullname
,a.value
,@searchterm AS SearchTerm
,DIFFERENCE(a.value, @searchterm) AS Score
FROM Application.People p
OUTER APPLY STRING_SPLIT(FullName, ' ') a
WHERE DIFFERENCE(a.value, @searchterm) > 3
) b
Please Consider Subscribing
