Problem
Recently I was approached with an issue which requires multiplexing queries in order to reduce the number of indexes created in azure search. Depending on the service level Azure allows only a limited number of indexes. In this particular case it was 3.
So if the customer has three tables and needed indexes on them we would have to create an index on each table individually. After which it would not be possible to create additional indexes within Azure Search.

The Solution
So the solution would be to union all the tables and create a single view using some kind of qualifier column to differentiate between rows belonging to different tables.
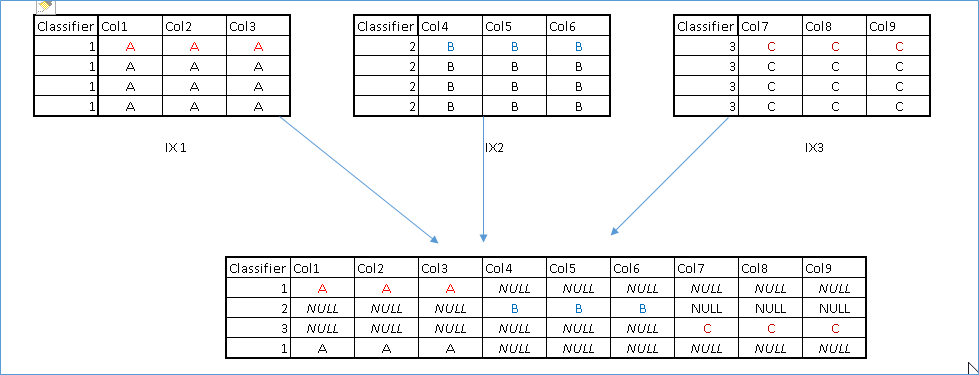
In order to achieve this we had two options which are listed below:-
Solution One
SELECT *
FROM (
SELECT 1 AS id
UNION
SELECT 2 AS id
UNION
SELECT 3 AS id
) c
LEFT OUTER JOIN (
SELECT 1 AS id
,year
,month
FROM january
) j ON c.id = j.id
LEFT OUTER JOIN (
SELECT 2 AS id
,airlineid
,flightnum
FROM feb
) f ON c.id = f.id
LEFT OUTER JOIN (
SELECT 3 AS id
,DestAirportID
,DestCityName
FROM [2014]
) n ON c.id = n.id
Statistics
Table ‘feb’. Scan count 2, logical reads 36066, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘january’. Scan count 2, logical reads 39530, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
CPU time = 1219 ms, elapsed time = 14389 ms.
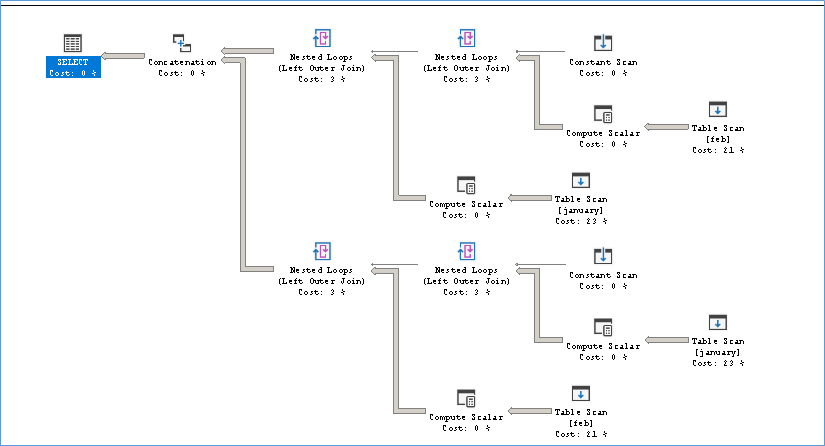
Execution Plan
Solution Two
SELECT 1 AS id
,year
,month
,NULL
,NULL
,NULL
,NULL
,NULL
,NULL
FROM january
UNION ALL
SELECT NULL
,NULL
,NULL
,2 AS id
,airlineid
,flightnum
,NULL
,NULL
,NULL
FROM feb
UNION ALL
SELECT NULL
,NULL
,NULL
,NULL
,NULL
,NULL
,3 AS id
,DestAirportID
,DestCityName
FROM [2014]
Statistics
Table ‘feb’. Scan count 1, logical reads 18033, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘january’. Scan count 1, logical reads 19765, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
CPU time = 781 ms, elapsed time = 13956 ms.
Execution Plan
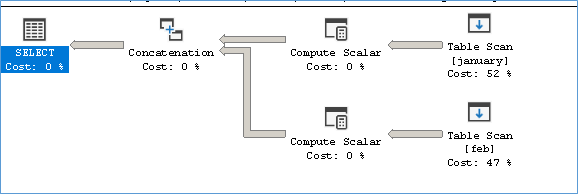
If you notice the stats you will see that execution time is similar for both queries but Solution 2 consumes less resources than 1. So how come? Well the second query is a UNION ALL so it reads table Jan and starts Feb only after Jan is over.
While Solution1 uses a LEFT OUTER JOIN and so can read the tables in parallel.
So which one should you use? It might seem obvious that we use the UNION ALL approach since its results in the least consumed resources. But we had to ask a question “What if we added more tables and each table is significantly larger” reading a table at a time means we simply add the read times for each table to get the total execution time. So wouldn’t it be better if we read in parallel?
The answer is NO, it’s still better to use UNION ALL instead. The parallel reads are offset by the number of iterations the nest loop has to do to return the results.
Please Consider Subscribing
