Recently I came across a requirement where we needed to load Resumes into SQL server and then search these documents for specific keywords. Important things to keep in mind included the use of SQL 2014, the resumes were in PDF format and the IO needed to be efficient. In this series of blogs I will show how we go about the process step by step.
The first step is to create a repository for the resumes, naturally we have a few options within SQL Server to achieve this. We could use a varbinary column but that would work well for cases where resumes where like 1 MB in size but that was an assumption we couldn’t make. Additionally they would add a serious overhead for SQL server LOB datatype search on the table and we wanted to improve the IO activity on the table there was also a case where resumes may be imported in BULK and we need a way to achieve that as easily as possible.
| Recently I have been using this approach in a number of cases for everything from resume search to document search as well as browsing crawled pages and much more. It’s a god example of how SQL can work well with unstructured data as well. The latest example is where I downloaded all my emails using GMAIL API and loaded them into SQL Server to find out email accounts where I receive the most spam or contacts I have interacted with professionally as well as personally. Check out the post where I created a network graph within SQL in the below section. |
Since we were using SQL Server 2014 we decides to go with Filetables.
First we enabled Filestream
See screenshot below to enabled Filestream from the configuration manager

sp_configure 'filestream access level’, 2
GO
RECONFIGURENext we created the database and added a Filestream Filegroup
ALTER DATABASE [ResumeDB] ADD FILEGROUP [Resumes] CONTAINS FILESTREAM
GONext we add a file (actually a folder) to the File group (replace the below path as needed, my blog doesn’t accept slash hence the word).
ALTER DATABASE [ResumeDB]
ADD FILE (NAME = filestream_data,FILENAME = 'C: (slash) Program Files (slash) Microsoft SQL Server (slash) DATA (slash) Resumes’) TO FILEGROUP Resumes
Next we give a Filestream directory name and set NON transacted Access to full so that files can be added directly into the folder without having to use SQL Server.
ALTER DATABASE [ResumeDB]
SET FILESTREAM (NON_TRANSACTED_ACCESS = FULL, DIRECTORY_NAME = N’Resumes’)Next we create an actual FileTable within SQL Server, this automatically captures metadata about the file like size, type, attributes etc., and it also keeps track of nested folders etc. and has functions exposed to navigate the filesystem. More importantly we can add files to the table without actually having to use Insert / Update / Delete, direct copy paste to the folder automatically reflects the changes.
CREATE TABLE dbo.ProfileResumes AS FILETABLE
WITH
(
FILETABLE_DIRECTORY = 'Resumes',
FILETABLE_COLLATE_FILENAME = database_default
)
GO
Loading files into the file table (simply copy paste)
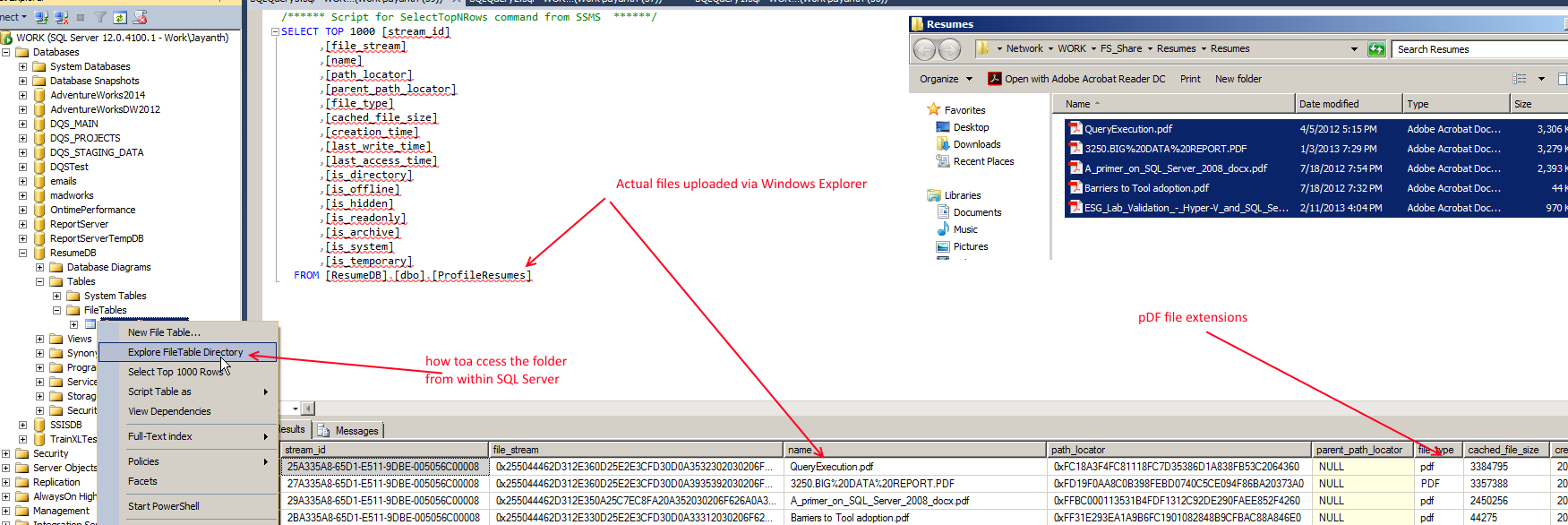
Now that we have a place to save our resumes the next step is to allow us to search the actual document content. Which we will explore in the next post.
Please Consider Subscribing
