
This was a question that came up during a SQL Session I conducted recently. We were reviewing some code in a procedure and it has logic similar to the query below.
SELECT *
FROM purpose_name
WHERE purpose_name NOT IN (
8872
,1239
)The question was , since that are only two values would it have been better to use the below query instead.
SELECT *
FROM purpose_name
WHERE purpose_name <> 8872
AND purpose_name <> 1239An interesting aspect of this question is the use of a scalar operator vs a Tabular operator. A scalar operation is one that equates to a single value for example the use of =, != , < , > are scalar in nature since they accept only one condition value against which the operation is performed. On the other hand you have tabular operators such as IN , NOT IN , EXISTS, IS NULL etc which evaluates over a set of rows and therefore can have one more values that are looked up against the same operator.
This question is a lot more elaborate than we give it credit for initially. Since the use of the operator does have an impact but the impact is subtle and can be missed easily if you are not looking for it.
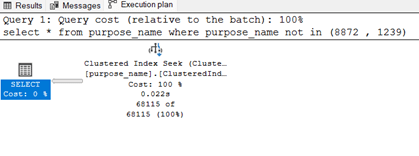
Lets start by running the below query and observing the results as show.
NOT IN
SELECT *
FROM purpose_name
WHERE purpose_name NOT IN (
8872
,1239
)Stats
SQL SERVER parse
AND compile
time: CPU TIME = 0 ms
,elapsed TIME = 0 ms.SQL SERVER Execution
Times: CPU TIME = 0 ms
,elapsed TIME = 0 ms.SQL SERVER parse
AND compile
time: CPU TIME = 0 ms
,elapsed TIME = 1 ms.(68115 rows affected) TABLE 'purpose_name'.Scan count 2
,logical reads 478
,physical reads 0
,page SERVER reads 0
,READ - ahead reads 0
,page SERVER READ - ahead reads 0
,lob logical reads 0
,lob physical reads 0
,lob page SERVER reads 0
,lob READ - ahead reads 0
,lob page SERVER READ - ahead reads 0. (1 row affected) SQL SERVER Execution
Times: CPU TIME = 0 ms
,elapsed TIME = 330 ms.SQL SERVER parse
AND compile
time: CPU TIME = 0 ms
,elapsed TIME = 0 ms.SQL SERVER Execution
Times: CPU TIME = 0 ms
,elapsed TIME = 0 ms.Completion
time: 2024 - 02 - 22
T12: 51 : 29.7320899 + 05 : 30
Execution Plan
Using <>
SELECT *
FROM purpose_name
WHERE purpose_name <> 8872
AND purpose_name <> 1239Stats
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 1 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
(68115 rows affected)
Table 'purpose_name'. Scan count 2, logical reads 478, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
(1 row affected)
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 339
ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Completion time: 2024-02-22T12:52:23.2941124+05:30Execution Plan
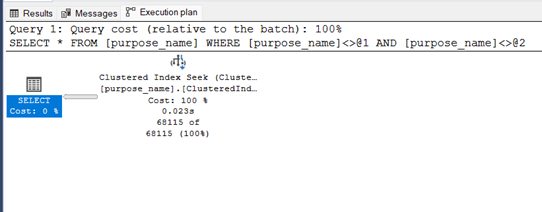
As you can see the only and probably important difference here comes down to “Do you want parametrization for the query?”
For queries where the values are hardcoded and the static (don’t change ever) you can use NOT IN as a filter criterion. However, if the values are subject to change, then for cases with small number of filter criteria it is worth considering the <> syntax. This automatically parameterizes the T-SQL optimizing it for other use cases as well.