I use the Random function quite a bit to generate dummy data. So recently I was interested to find out actually how random it is. Randomness implies that all possible outcomes have an equal probability of happening and therefore cannot be predicted in advance. Since the outcome can’t be predicted it is pure chance and therefore random.
Under this assumption we should; over a suitably long period of time see almost all number repeated an equal number of times and over a short period generally the number doesn’t repeat itself.
The test for this is fairly simple, insert a million rows into a table and count the number of times the values occur.
While inserting the rows we realize that the randomness is also impacted by the cardinality of the data. For example a coin has only two states so a test of maybe ten flips should be enough to verify the randomness of the coin. A dice might need much more iterations to ensure that it is in fact random similarly a random number generator could theoretically require an infinite number of iterations before it can conclusively be deemed random. This might sound ridiculous initially because we might have one million unique numbers which is sufficient to prove that it’s random but it doesn’t conclusively prove that there is a certain number it’s trying to avoid. If a die is cast such that it never lands on six you can find that out after about 30 rolls. But how do you do that for something like RAND()?
Mathematically if the probability of one state is reduced then the probability of all other states is improved proportionally.
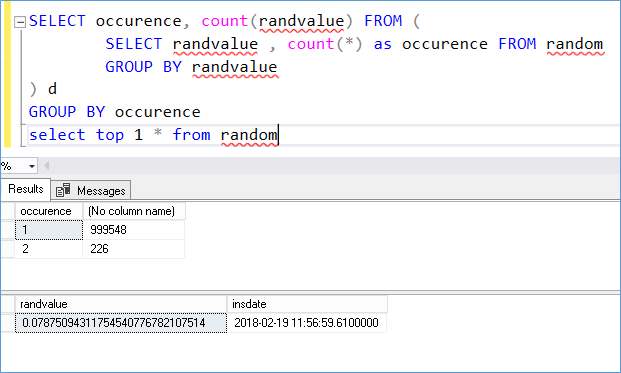
Notice how in the below test despite how cardinal the data in randvalue is we see there are duplicates (226). There is an infinite series of numbers that could be explored in the decimal places but we still end up with duplicates.
But scientific method requires that the test be repeatable so we do this again.
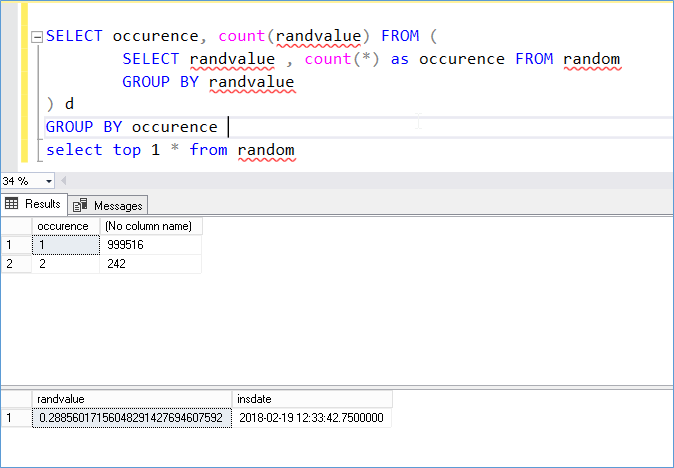
Second time around we see comparable results to the first run. At this point it’s safe to say that the RAND() function is not truly random.
Just to be sure we run the same test with only 100K iterations (maybe the duplicates are cause by the values rolling back on themselves). We see that even for 100K iterations we encounter duplicates. Well before other options are explored.
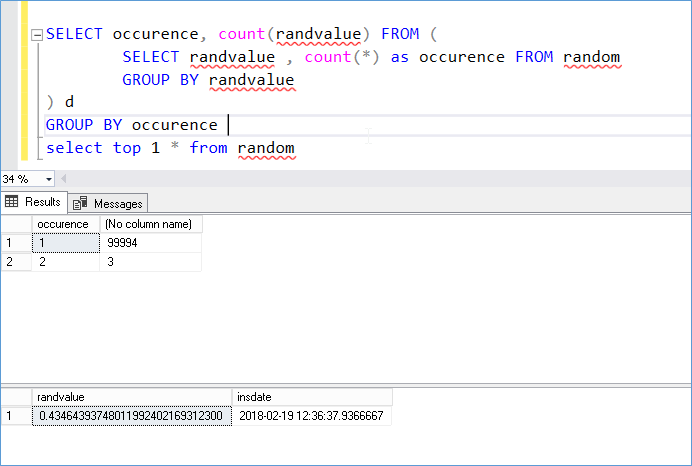
So why does this happen? The RAND() function actually expects a seed value which if not provided by the user is automatically assigned by SQL Server itself.
The seed value can be tinyint, smallint or int datatypes. For any input seed value an equivalent random number is generated. So you see that RAND() function is more like a hashing algorithm – for a given input there is always the same output. Basically what this means is “while the output or random function appears to be a random number the probability of that number being generated is not exactly pure chance”. If the seed value is int then there are only 2,147,483,647 possible inputs and as a result the same number of outputs.
In order to be truly random the function needs to be aware of previous output values and ensure they do not repeat. This way every value has an equal probability. However this can be extremely resource intensive so not really practical. The other option is to build into the logic some inherent randomness such as quantum randomness from the atomic level. Thanks to big bang theory I am sure everyone is aware of Schrodinger’s Cat now. Or use cosmic background radiation or gamma particles to seed randomness into the chip level design itself.
The more we use statistical analysis to improve machine learning, AI, game theory etc. the more important it becomes to define what random chance is. And how not everything that seems random actually is. But that’s a topic for Chaos theory and another day.
Please Consider Subscribing
