A bit late in the day but I figured I would add a post on how to configure MS SQL Server Polybase. Polybase is a feature of MS SQL server I don’t see many customers using but it is still very exciting since it make SQL Server truly the single data platform any company needs to manage any volume of data.
The feature itself is not new since it used to be called Parallel data warehouse in SQL 2014 and it does pretty much the same thing now that it did then. Expect for the fact that it comes as part of the SQL Server installer instead of a black box. Essentially it allows relational database query constructs against CSV files sitting in a Hadoop file system. The idea being you might have terabytes of data sitting in CSV files in a HDFS and you want to query portions of it without having to use the Hadoop infrastructure to do it.
Think of it like creating a linked server connection to a flat file except the flat file is sitting in a Hadoop hdfs file system or azure blob storage.
Installing Polybase is fairly straightforward it require Java Runtime to be installed which you download from here.
Then you simply check the box to install Polybase Query Service for External data
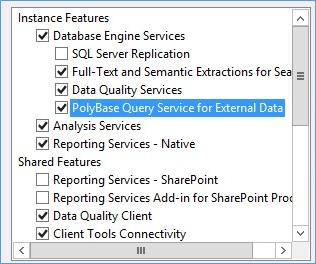
The next Polybase screen you will see is the one below where you tell SQL Server if the installation of Polybase is a standalone instance or part of a scale out group. A stand alne instance has a head and compute node and acts independently. While as part of a scale out group other instances can take part in providing compute operations for large data sets.
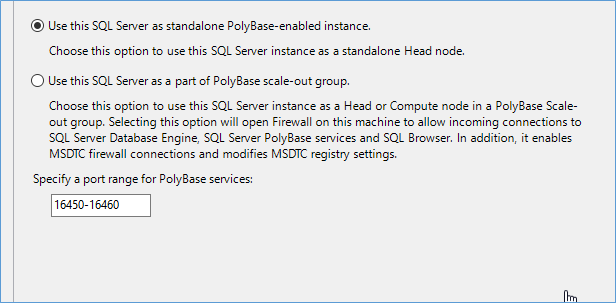
Open firewall ports as needed if your configuring a scale out group.
One this is done Polybase will be installed on the system and you will get two additional services installed.
![]()
![]()
Make sure they are both running and if possible within the same account as other nodes in the scale out group i.e. within the same domain. If the Polybase Engine doesn’t start verify TCP/IP is enabled and the SQL Server instance is running.
If the services are running you can add additional compute nodes to your scale out group by using SSMS as shown in the screen below.


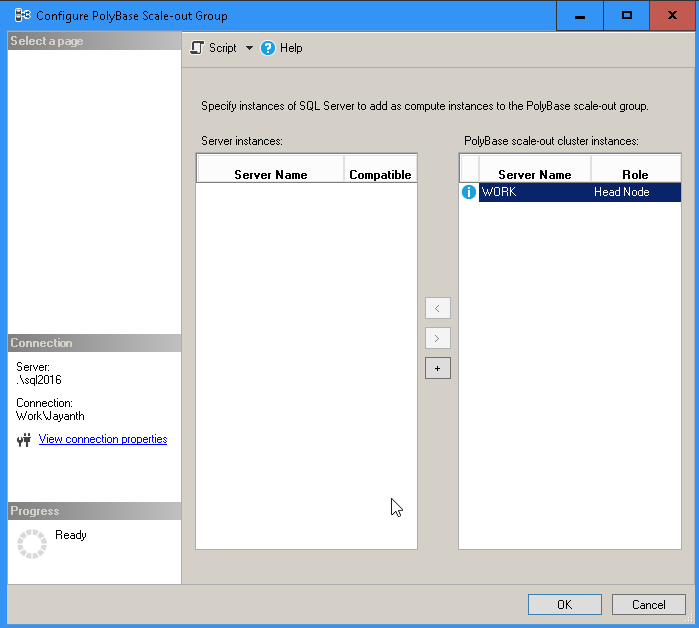
With the above done we are ready to get started configuring Polybase.
The first thing we need is to upload a CSV file containing some data into Azure Blob Storage account. Quick intro into the process can be found here.
Once the file uploaded you can start running the script below to setup Polybase to read the data off the csv file stored in the storage account.
USE master;
GO
-- shows the advanced option for hadoop connectivity
EXEC sp_configure 'show advanced option'
,'1';
RECONFIGURE;
GO
-- the number 4 in the setting below refers to azure blob storage
-- look up the appropriate value for your stoage system from the link below.
--https://docs.microsoft.com/en-us/sql/database-engine/configure-windows/polybase-connectivity-configuration-transact-sql
EXEC sp_configure 'hadoop connectivity'
,4;
GO
RECONFIGURE;
GO
-- create and use a database as needed
USE Madworks
GO
-- since data needs to move over the network a master key is needed to enrypt the data moving to and from azure
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'Something@Secure';
GO
-- the credential below is required to stroe the access key to the blob storage account .
-- this acts a username and password for local SQL server to access the azure resource in the cloud.
CREATE DATABASE SCOPED CREDENTIAL mycredential
WITH IDENTITY = 'credential'
,Secret = 'T4TX120D1ivxbKrYi4Goc6L2op4KSfKN3h8lVLslREWsaTa1o3mvgyfpIByvSGva/Kj9sF6DGT3QFcP/VgwH1A=='
GO
-- next we need to tell SQL Server where the data is located within azure.
-- essentially a account can have mutiple storage accounts with multiple containers etc so we need to reference
-- the storage account and the container within it that has the files we are looking for with the credential we just created
CREATE EXTERNAL DATA SOURCE AzureStorgaeDataSource
WITH (
TYPE = HADOOP
,LOCATION = 'wasbs://polybase@polybasejayanth.blob.core.windows.net/'
,CREDENTIAL = mycredential
);
GO
-- next since its a csv file need to tell Azure how to read the CSV file and understand the columns and datatypes assocaited with it
CREATE EXTERNAL FILE FORMAT userscsvfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT
,FORMAT_OPTIONS(FIELD_TERMINATOR = ',')
);
GO
-- lastly we need to create a connection using the datasource we created before and the format file to a imaginary table within SQL Server
-- this way sql server has what looks like a typical table but actually access the data from the azure blob storgae
-- this allows us to query the table just like any normal relational table without having to worry about the fact that the data
-- is actually comming from Azure
CREATE EXTERNAL TABLE tblcustomers (
f_name VARCHAR(200)
,l_name VARCHAR(200)
,email VARCHAR(200)
)
WITH (
-- location='/" just means all csv file under this path.
LOCATION = '/'
,DATA_SOURCE = AzureStorgaeDataSource
,FILE_FORMAT = userscsvfileformat
)
GO
-- finally we are ready to query the external table and access the data just like we always do.
SELECT f_name
,l_name
,email
FROM [madworks].[dbo].tblcustomers
What this allows us to do is bring in small datasets for analysis from within Hadoop without having to know anything about Hadoop implementation. Making ad hoc analytics much more user friendly. Also often we use Hadoop to crunch the numbers and summarize information that can then easily be stored in traditional relational tables for better reporting.
Please Consider Subscribing
