Accelerated Database Recovery is a feature that DBAs will find very useful. Dba’s are often stuck in a situation where the transaction log file cannot be truncated because of a long running query or the database recovery takes longer than usual after shut down and restart. In such scenarios Accelerated database recovery is the feature that will allow the server to recover a DB as soon as possible. If you are familiar with the old method then you know that there are 3 stages to recovering a database the first being in Analysis phase the second the redo phase and the last being the undo Phase period.
Typically, the speed of recovery depends on the oldest running transaction. The speed of the database recovery is dependent on the number of transactions that go through these different stages. By using accelerated database recovery or ADR we are able to speed up this whole process by using a number of different mechanisms. In order to understand this let’s consider that we are talking about a transaction in a car wash. Under normal circumstances we have a customer who drops off a dirty car and then we spend a certain amount of time cleaning it up at the end of which we get paid. This can be considered like a transaction that has started performed some DML operations and then committed upon successful completion.

Now let us consider that after we finish doing the car wash the customers unsatisfied and refuses to pay money. Naturally we want to bring the database back to a consistent state and therefore we find a bucket of mud and pour it all over the car in order to make it dirty again hence restoring the page back to its original state.

Unfortunately following this process requires us to spend almost the same amount of time making the car dirty again compared to cleaning it up and this results in pretty much double the effort. Avoiding this step is a key reason why ADR is as fast as it is.
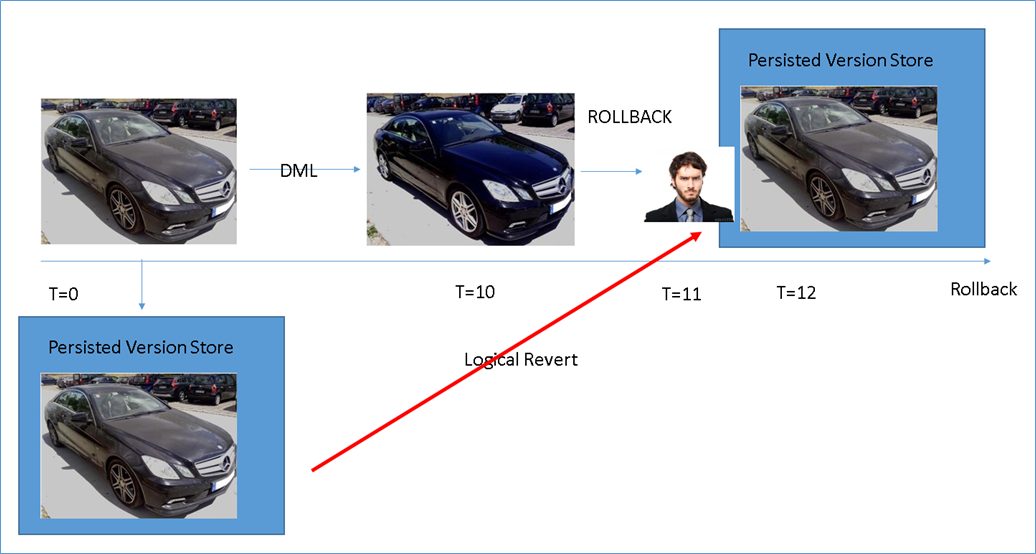
Now let’s consider a car wash where the customer drops off their car and we instantly create an exact replica of The Dirty car and store it in a safe location. This copy is inaccessible to the customer and is only meant for us in the event that we need to rollback. In SQL Server parlance this is called a persisted version store and is similar to the optimistic concurrency snapshot isolation version store. As we clean the car this original version of the page still resides and is available at an instance notice in case we need to rollback. If everything goes smoothly, we finish the DML operation and the customer never needs to find out about the persisted version store.

However, in the event that we need to do a rollback rather than try to undo changes we will now simply release a lock on the persisted version store and present that version to the customer. This is the same as the original version of the page before we started cleaning it up. You can naturally see why this would. This process of presenting a copy of the data from the PVS is called a Logical Revert.
The below screenshot shows what a normal recovery looks like, notice it took 171 seconds to recover the database with 14 sec for Analysis, 82 sec for redo and 73 sec for undo.

The below screenshot shows the difference when using ADR for the exact same query.

As can be seen from the screenshot the database is recovered in 18 seconds and undo phase took just 78ms since its just reverting the PVS.
So what is the sLog?
It’s a secondary log which captures details for transactions that do not have any version store info e, g DDL statements Bulk insert, Locks acquired etc. Think of it like taking a lunch break in the middle of washing the car. Regardless of the end state of the car you’re not going to undo your lunch break when the transaction gets rolled back. So these transactions get put on a fast track ( sLog) for redo undo phase.
So what’s the catch?
Just like tempdb for optimistic concurrency there is a size overhead for the data file when storing row versions but the overhead is well worth the cost for the much for efficient management of the transaction log file. After managing the tlog size is where the database administrators spend a lot of time.
Please Consider Subscribing
