An interesting problem came up in #SQLHelp today. The query is fairly simply and aims to generate a random distribution of value 1,2 and 3. I am not sure of the use case for it but this is what the code tries to achieve.
SELECT choose(abs(checksum(newid())) % 3 + 1, 1.0, 0.6, 0.3)When the above block is executed multiple times we encounter a situation where the result of the above query is sometimes NULL. The question is why?
Let’s break down the problem is little further. The first thing to note is that the below code will always return a value between 1 and 3. It doesn’t not return NULLS or any other value.
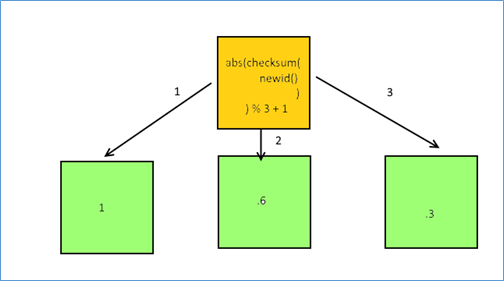
abs(checksum(newid())) % 3 + 1The below diagram explains the flow a little more clearly. The expectation is that first the orange block will run and then based on the output one of three possible paths may be taken.
This above flow makes lot of sense based on how we see the code being written. However we need to consider the unique nature of the CHOOSE function. It is essentially a CASE statement without an ELSE BLOCK. So the actual flow as far as SQL Server is concerned is more like the below diagram.
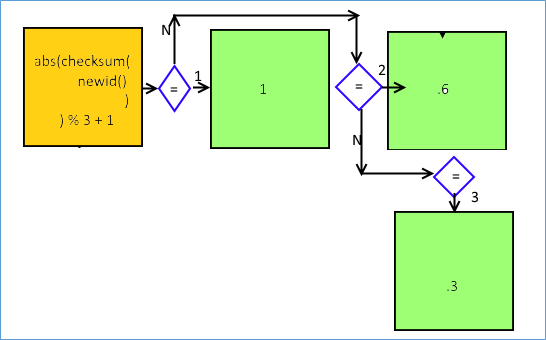
Notice how in the above case the operation is more serial in nature, because the check is performed three times, compared to our original assumption (the check is performed once and then simply directed to the corresponding block). In other words the query would be rewritten as below
SELECT CASE
WHEN abs(checksum(newid())) % 3 + 1 = 1
THEN 1
WHEN abs(checksum(newid())) % 3 + 1 = 2
THEN 0.6
WHEN abs(checksum(newid())) % 3 + 1 = 3
THEN 0.3
END
But even in this case we should default to one of three possible values i.e. after the orange blocked is evaluated we would still end up with values 1,2 or 3 so the execution ( serial or parallel ) should still return a value from the green block. And here is where the OP made the mistake. The value of NEWID() changes with every call.
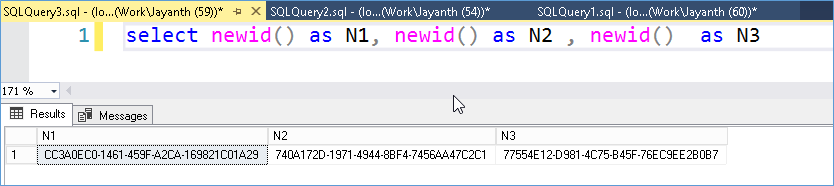
In the below screenshot notice how even when called within the same row in the same statement it has different values.
Because the value of newid changes with each call the actual execution flow of the query looks like this. With execution of newid() the value just misses the case statement condition that needs to be satisfied and is thus able to traverse the logic without being caught in any single condition.
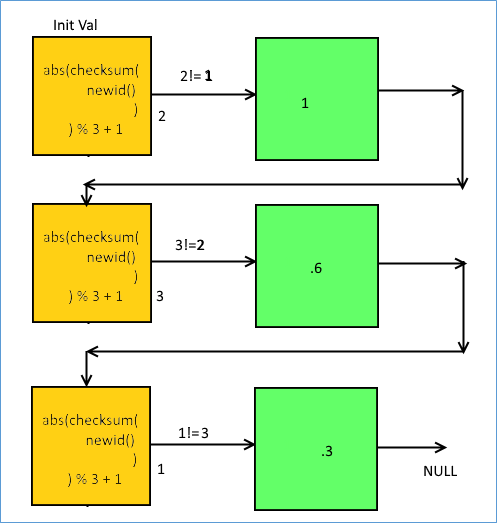
To avoid the problem the OP should have written the query as below , so forcing SQL Server to use the persisted value of NEWID() till it reached the end of the case statement
DECLARE @newid UNIQUEIDENTIFIER = newid()
SELECT @newid
,abs(checksum(newid())) % 3 + 1
,choose(abs(checksum(@newid)) % 3 + 1, 1.0, 0.6, 0.3)
,abs(checksum(@newid)) % 3 + 1
While writing tis post it occurred to me that this behavior has a very close similarity to something in quantum physics called superposition. In simple terms Superposition states that an electron can be thought of as being in multiple states until the time that it is measured. In other words the cat is both dead and alive and the true value can only be derived by measuring it. Much like our NEWID() where until we measure it , it’s thought to occupy all possible states and depending on when we measure it the value will converge to any of the possible states or none at all.
Please Consider Subscribing
