I read a very informative post today on Linkedin about how developers sometime don’t understand the impact of using table valued parameters in a stored procedure. A table valued parameter allows developers to pass an array or table in one call to a stored procedure. So it’s basically passing a table as the input. The post goes on to explain that because TVP do not have statistics they hinder the execution plan when it comes to optimizing the code. It further recommends that the developer move data from the TVP into a temp table (which has statistics created for it) before running the logic.
This got me thinking about the behavior of the Optimizer when it starts using the TVP and Temp table, e.g. would the overhead of loading into temp table, calculation of stats and the recompile effort be worth the improvements in performance if any?
To start off I create a table variable data type
CREATE TYPE LocationTableType AS TABLE (
rid INT
,[OriginCityName] VARCHAR(200)
,[OriginStateName] VARCHAR(200)
,[DestCityName] VARCHAR(200)
,[DestStateName] VARCHAR(200)
);Then I create my procedure which calls the TVP as an input variable.
CREATE PROCEDURE checkrecompile @Location LocationTableType READONLY
AS
SET NOCOUNT ON
SELECT *
INTO #location
FROM @Location
SELECT [Year]
,[Quarter]
,[Month]
,Count(*)
FROM On_Time o
INNER JOIN #location l --inner join @location l on l.rid = o.rid GROUP BY [Year], [Quarter], [Month]
Once done I start calling the above procedure for two different use cases, One in which we pass only 100 rows into the TVP and another with 100000 rows to see the impact.
DECLARE @Location AS LocationTableType;
/* Add data to the table variable. */
INSERT INTO @Location (
rid
,[OriginCityName]
,[OriginStateName]
,[DestCityName]
,[DestStateName]
)
SELECT TOP 100000 rid
,[OriginCityName]
,[OriginStateName]
,[DestCityName]
,[DestStateName]
FROM on_time;
PRINT '$$$$$$'
The below execution plan shows the behavior when using TVP with 100 rows as the input, you can ignore the plan in Query 1 because that is used to populate the variable (something usually done via application). This query takes on average 1 ms.
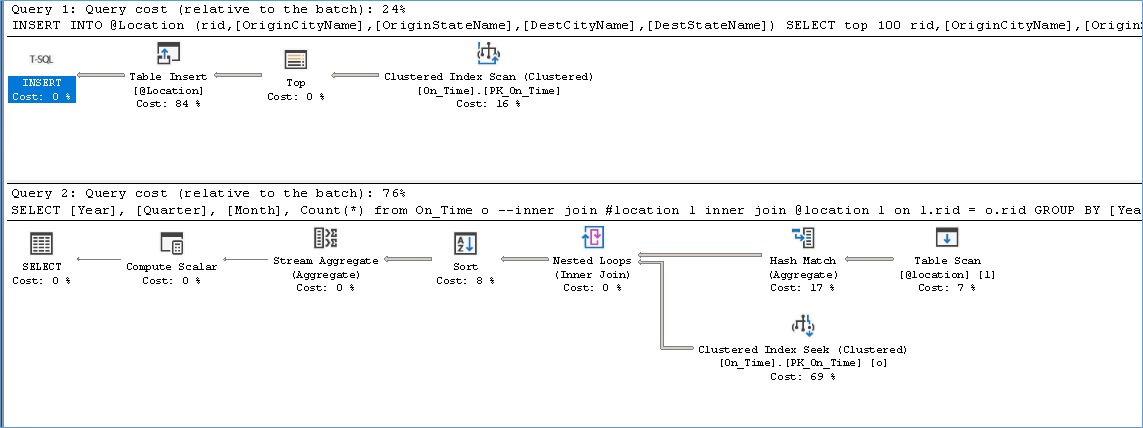
The next execution plan is for 100000 rows in a TVP, This query takes on average 850 ms

Notice the warnings that arise due to insufficient memory grant causing the spill to tempdb hence the requirement for statistics.

From the above we can see that using a TVP doesn’t change the execution but causes inefficient memory utilization for workloads that have very different patterns.
Now we change the procedure code to store data from the TVP into a temp tale before running the join and group by
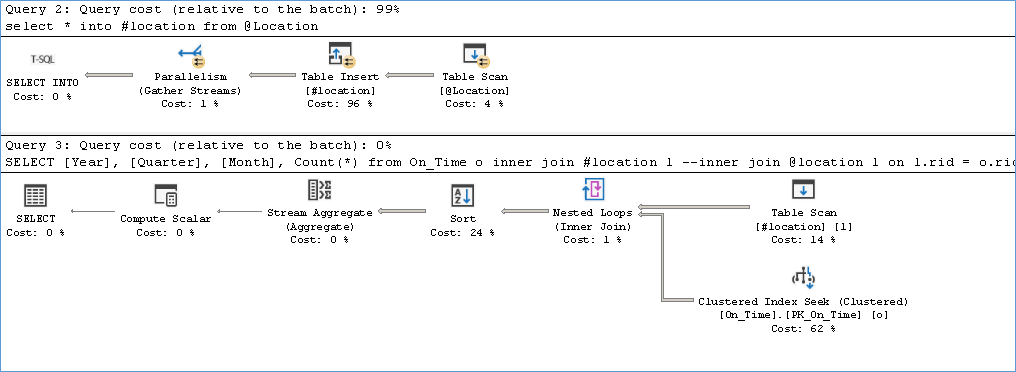
The below execution plan show the performance for 100 rows, here we see two plans the first for loading the data into temptable and then for the query execution. Notice how it isn’t very different from the plan we had for a TVP except for the HashMatch. This query takes 5 ms to complete as opposed to the 1 ms for the TVP
before but if we execute the same code once more the execution time dips to 1 ms. because the recompile overhead is no longer there. However if I switch to 100000 rows and then back to 100 rows we again encounter the recompile overhead.
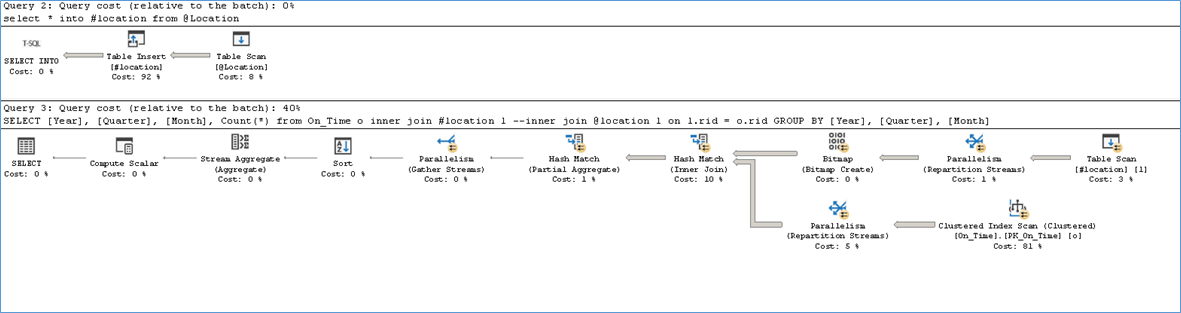
Now let’s explore the TempTable logic with 100000 rows
/* Pass the table variable data to a stored procedure. */
EXEC checkrecompile @Location;
GO
As you can see we now benefit from parallelism due to statistics being available for data in the temptable. As a result we get a significantly different execution plan too. The above query takes on average 321 ms compared to the TVP which had an execution time of 850 ms. So we definitely see the advantage of using TempTables when it comes to large number of rows. Naturally we see increased CPU usage but that is a good thing considering the number of rows we are dealing with.
If the above procedure is recompiled due to changes in the number of rows we still see only an additional 73 ms overhead which answers the question of recompile for large data sets.
Summary
Using a TVP makes sense for small datasets (typically a few hundred rows)
Using a TVP also makes sense if the Server is already CPU bound or not TempDB optimized
Using a TempTable makes sense for large datasets (typically many thousands of rows)
For patterns where there is a frequent fluctuation in the number of input rows to the TVP it make sense to use TVP if the majority count is few hundreds ( its much better to have a query that takes 1 ms vs a query where recompile takes 6ms ) else use a TempTable ( it’s much better to have query that recompiles in 73ms than a query that doesn’t and still takes 3 times more time).
References
- http://blog.sqlgrease.com/table-valued-parameters-performance/
- http://blog.sqlgrease.com/table-valued-parameters-performance/
Please Consider Subscribing
