Occasionally there may be a need to manually process the cube. This would occur when the cube design has not changed but new data has been imported into the underlying database tables. Most of the time the developer would create an SSIS package that will automate the activity of processing the cube. However let us first explore the way to manually process the cube using the SSMS interface. In a future post we will explore the option of creating a Package.
Open SSMS and connect to the Analysis Services Engine.
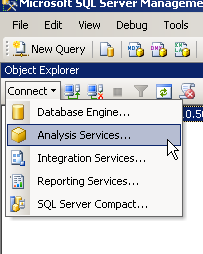
In the “Connect to server” window entre the name of the server on which the cube has been deployed. Note that SSAS doesn’t support any other type of login except for Windows authentication.
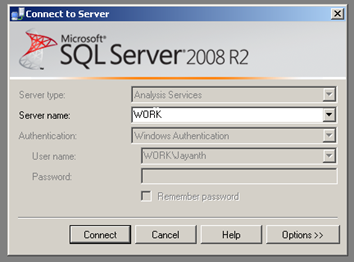
Once connected, you will see the cube and the different parts of the cube listed on the object explorer window
As mentioned in the previous post it is important to process the cube to do mainly the following things.
- Identify new records that have been inserted in the dimension tables and fact (measure group) tables
- Aggregate the data in order to ensure common measure and dimension data is already pre calculated.
This means that we can process dimensions individually or measures individually as required.
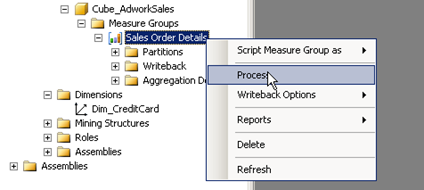
Or we can process the cube completely in order to make sure both are consistent. The order in which things need to be processed is Dimensions first followed by cubes. The reason for this is due the logical primary key (dimension table) and foreign key (measure group table) that exists. In order to process a dimension simply right click the dimension and select Process
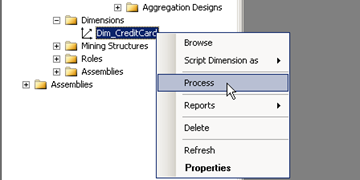
In our case this would be Dim_CreditCard
The same process should be repeated in order to process the cube by selecting the measure and then pressing process.
Let us explore the options that we get when we try to process the dimension. As soon as you press Process the below screen will appear.
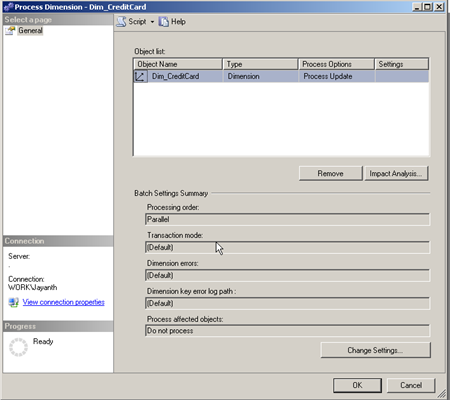
The window provides some information about the dimension you are trying to process, if you click the Impact analysis button on the top it will list the additional objects that will be impacted as a result of processing the dimension. If you click on the text in the Process Options column of the above screen you will get a number of options. We will explore the meaning of each of these options in the next post.
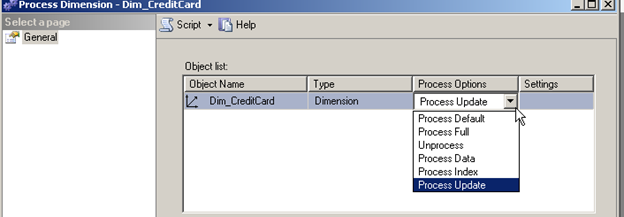
For now leave it at process update.
If we click the “change settings” button on the bottom half of the screen. We will see the below window
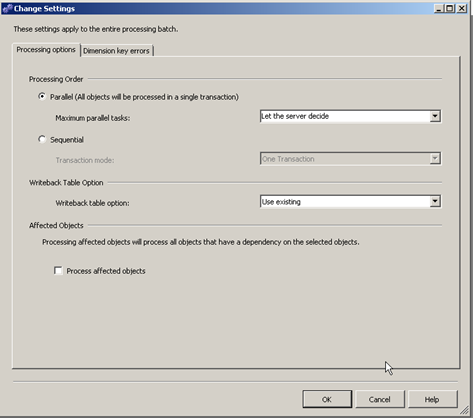
This window allows us to configure or change the way the dimension gets processed. The first half affects the processing order. This means we can process the dimension in Parallel (this feature is not available lower editions of SQL Server, use Enterprise edition). The Maximum parallel tasks usually works better when the option is Lets the server decide. However we have the option of specifying the details
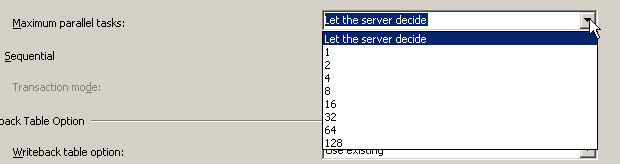
The parallel tasks here are similar to parallelism we have in the database engine.
The next option is Sequential this is the only option available in lower editions

We can choose to process the entire dimension as a single transaction or as separate transactions. The idea here is that when processing the cube will run a query to identify distinct values in each column of the base table this can be done as a single transaction or as separate transactions. Here is what msdn has to say about single transaction vs separate transactions.
“
One Transaction. The processing job runs as a transaction. If all processes inside the processing job succeed, all changes by the processing job are committed. If one process fails, all changes by the processing job are rolled back. One Transaction is the default value.
- Separate Transactions. Each process in the processing job runs as a stand-alone job. If one process fails, only that process is rolled back and the processing job continues. Each job commits all process changes at the end of the job.
When you process using One Transaction, all changes are committed after the processing job succeeds. This means that all Analysis Services objects affected by a particular processing job remain available for queries until the commit process. This makes the objects temporarily unavailable. Using Separate Transactions causes all objects that are affected by a process in processing job to be taken unavailable for queries as soon as that process succeeds.
”
Writebacks will be covered in detail later, for now we move on to the next option which is the process affected objects.

Select this option if you want to make sure any dependent objects are also processed, it is advisable to try processing individually first before processing the dimension this way. Selecting this option can increase the time taken to process a dimension and can result is problems if processing of a dependent object fails.
The next Tab is dimension Key errors; we will explore this tab separately when we add our next dimension. For now Press OK and process the dimensions.
If processing when thru fine you will see the below screen. Notice the different rows and details of the count of distinct values in each column.
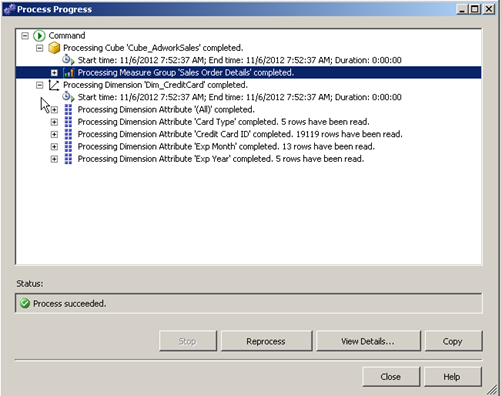
The same screens are available when processing the measures with a few exceptions in terms of processing options.
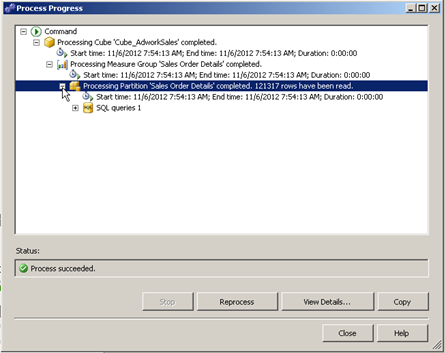
Notice that when you process the measure there is no mention of the dimension in the output.
Please Consider Subscribing
