In the last post we ended with two questions remaining unanswered.
Shouldn’t a more accurate row count have resulted in the correct amount of memory being granted and more importantly why didn’t intelligent Query processing detect and correct the issue in subsequent runs?
We were exploring the improved performance of Table Variable deferred complication to see if it provided a better query execution time and it did. But we still encountered that TempDb Spills were occurring. In this post we find out why?
The query we were working with is mentioned below for your reference. Notice that the index create portion is commented out.
DECLARE @tablevariable TABLE (
customerid INT --primary key clustered
)
INSERT INTO @tablevariable
SELECT customerid
FROM customers
WHERE IsMember = 1
SELECT customerid
,password
FROM Customers
WHERE customerid IN (
SELECT customerid
FROM @tablevariable
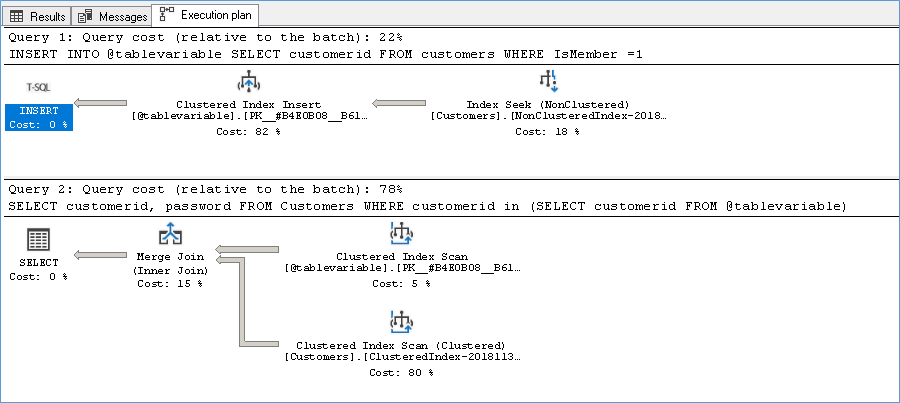
)As seen previously we have a Hash Match (aggregate) Operation
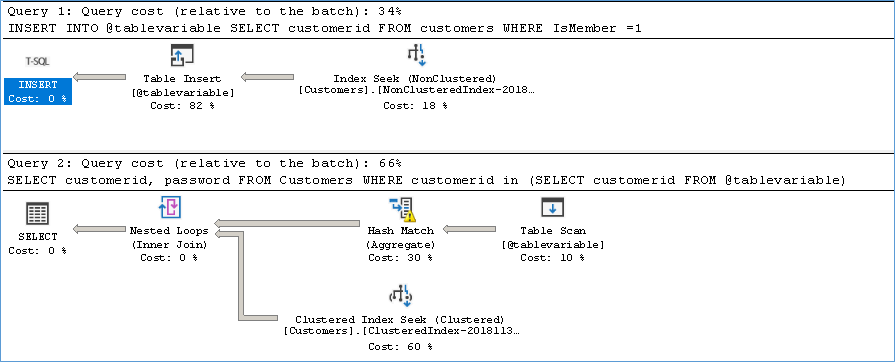
If we understand the Hash Match operator properly we see that a temporary hash table is created with hash values for each row, much like how a Hash Join works.
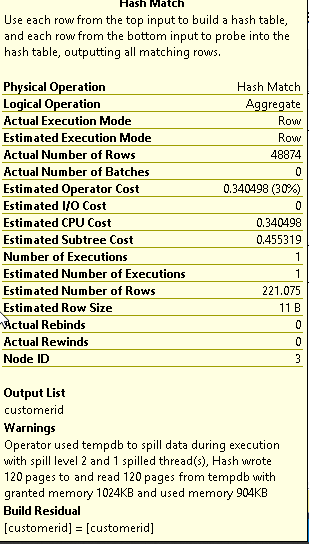
Once the hash table is created we see that a nested loop join is probing the hash Match operator with rows from the Customer table. This is done to satisfy the IN Criteria of the above query.
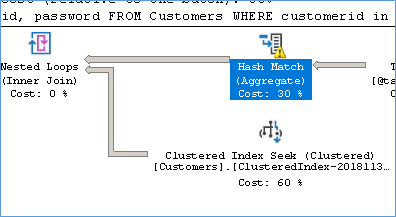
Because the customer table is huge and we are performing a row by row probe see the number of executions that happen in the Customer table. #ofExec=48874, #ofRows=1
Instead of reading all rows are once we one row being read per execution. No Doubt in this case we would much rather prefer an Index Scan than Seek.
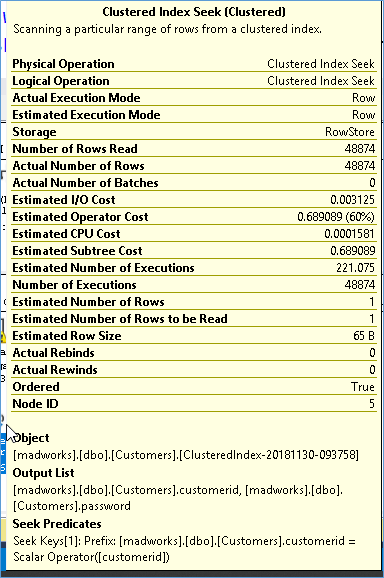
So why did the optimizer decide to do it this way? Well the simple answer is we have an index on the customer table to help identify the rows but not on the Table Variable which now needs to loop customers table for each row it contains. In order to allow both tables to be able to search each other properly we need to first put an index on the table variable which is why we can now uncomment the index create portion in the above script. As soon as the index is created the data in the Table Variable is sorted so we don’t need to scan the entire customer table for each row in the table variable and suddenly our Nested Loop join turns into a Merge Join requires far fewer pages and thus eliminating the table spill.
In this case we don’t see any marked improvement in the execution time we see that there is a significant improvement in IO characteristics on the above query due to avoiding the TempDB spills.
Before
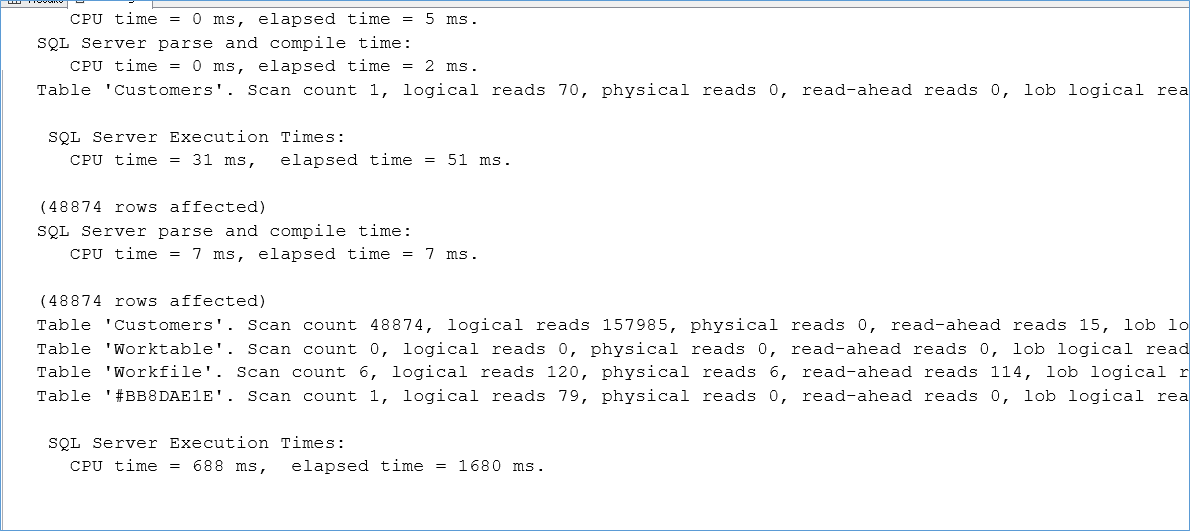
After, notice how we don’t scan the Customers table 157985 times anymore. In other words the optimizer decided it won’t need RAM for that many pages and since I don’t have that much RAM anyway we avoid spilling to TempDB.

So that is how the Spills have been avoiding in this query. In the next post I enable intelligent query processing to see how it would have tuned the above code. As a excersice what do you think would have happened if we has simply rewritten our original query like below:-
DECLARE @tablevariable TABLE (
customerid INT --primary key clustered
)
INSERT INTO @tablevariable
SELECT customerid
FROM customers
WHERE IsMember = 1
ORDER BY customerid
SELECT c.customerid
,password
FROM Customers c
INNER JOIN @tablevariable d ON d.customerid = c.customerid
ORDER BY d.customerid
Please Consider Subscribing
