Scalar UDF are notorious for their performance issues. The most common reason they cause issues is due the fact that the logic is applied on each row. So queries which use Scalar UDF for a large number of rows often face significant execution times due to the context switch with each row. There are other factors like optimizer not taking into account the scalar UDF internals for costing etc. But by far the biggest impact is due to the row by row execution.
The previous logic was such that a pieces of logic is applied to each row. However with SQL 2019 we have optimizations that allow the database engine to review the logic of the Scalar UDF and then modify the query plan such that the UDF logic is written in line with the calling query. This gives the optimizer a bird’s eye view of the query logic and the UDF logic and their points of interaction. Therefore resulting in better plans and costing. Additionally it allows operations to be performed on a batch of data as we shall see later.
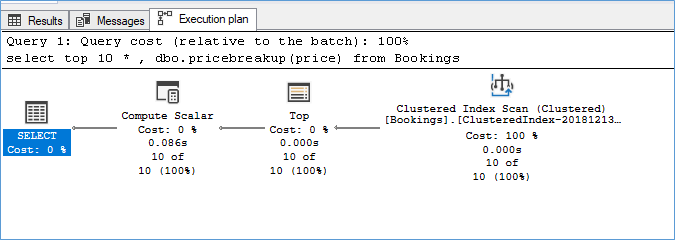
This is an example of the execution plan without Scalar UDF inlining
Execution time
SQL Server Execution Times: CPU time = 4438 ms, elapsed time = 4473 ms. |
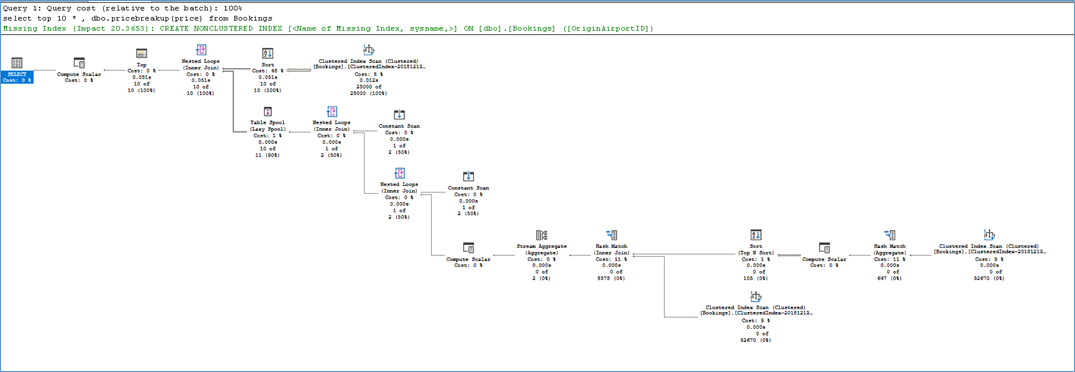
This is an example of the execution plan with Scalar UDF inlining
Execution time
SQL Server Execution Times: CPU time = 78 ms, elapsed time = 51 ms. |
Also notice how in the second execution plan we get a missing index warning because the optimizer has more visibility into the logic of the UDF.
What’s the Catch
Not every Scalar UDF can be inlined. There are some pretty serious gaps that prevent a lot of UDFs from being inlined e.g
- They should contain an if else block
- UDF is not part of order by / Group by clause
- UDF cannot reference table variables
- Use GetDate
- And more.. read here for the complete list.
So would I use it?
Yes, despite its limitations the performance improvement it can deliver when it works is well worth the effort.
Please Consider Subscribing
