If you have been following the buzz around MS SQL 2016 you would surely have heard of Stretch database. The concept is interesting and new and probably something we could have used even in SQL 2014. I know a few clients already using Azure data sync to move historical data to the cloud I can’t comment on the economic viability of offloading historical data to the cloud since I would prefer not being billed at all for data I don’t use but that’s just me. In this post I try and cover this feature in as much detail as I can.
So what is stretch database?
This feature allows the DBA to move historical data to the cloud, therefore leaving the current OLTP data on premise and the historical data in a secondary cloud location where it is still seamlessly queryable. Potential benefit include cheap storage of billions on rows of archive data without the data management headaches that come with it. Potential disadvantages include limited functionality of the tables where this functionality is being used and slower query response time due to network IO.
How do you enable it?
sp_configure 'remote data archive',1
GO
RECONFIGURERun the below query to enable Remote Data Archive at the server level
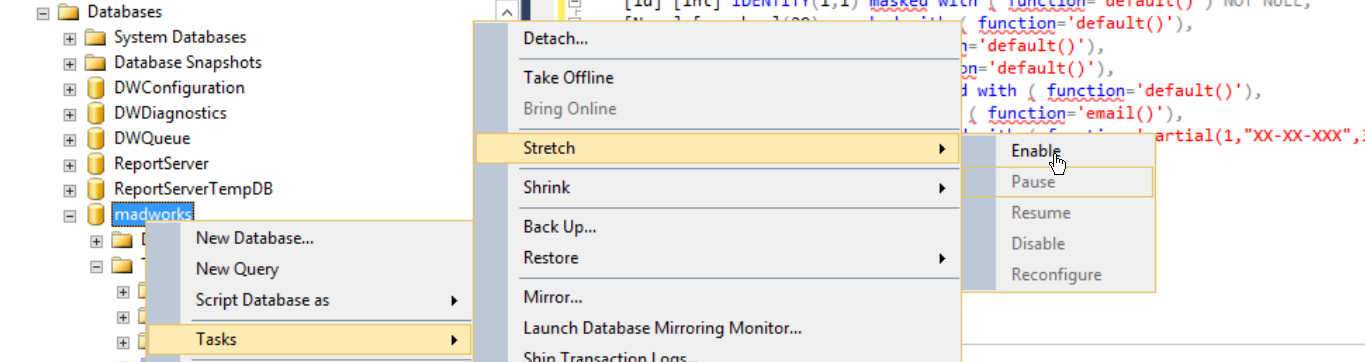
Follow the steps in the below wizard
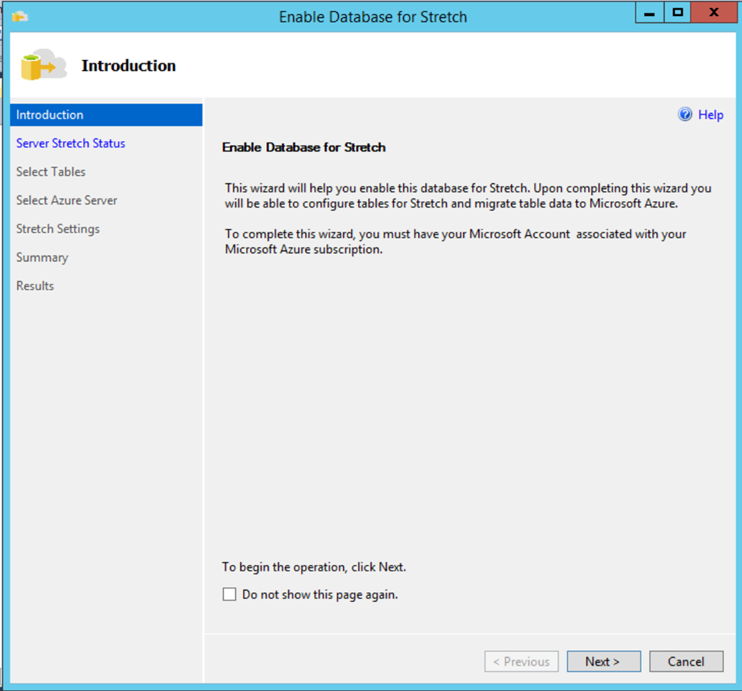
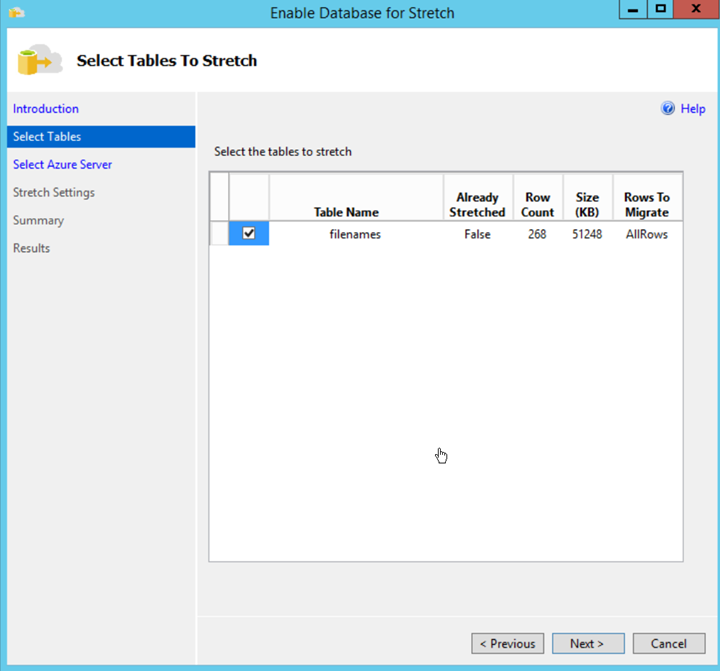
Select the tables you want to push to the cloud
Login to the Azure account
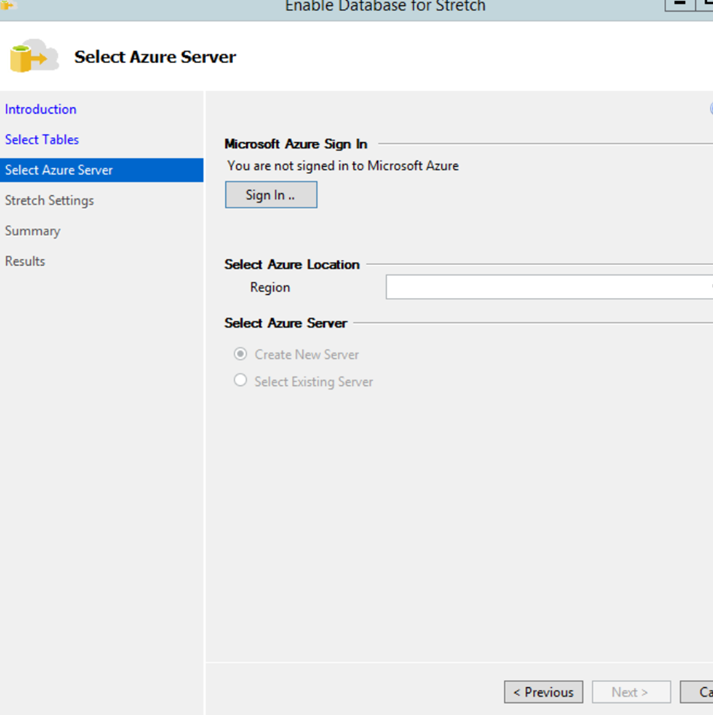
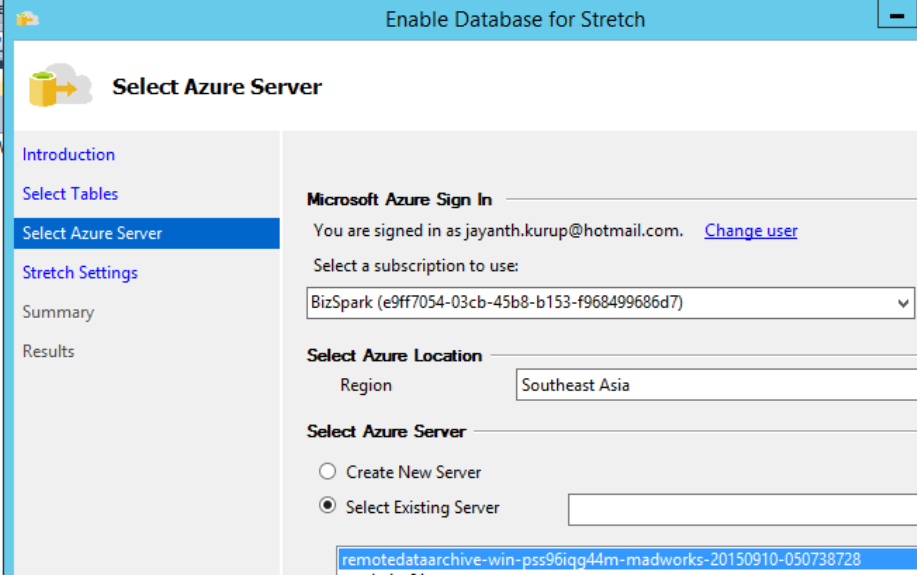
Note it’s always better to make sure you use a domain authenticated account when connecting to Azure, so it’s going to require both DBA and Network admin to setup and configure the VPN to allow users and machines to connect seamlessly in a hybrid environment.
Enter the azure credentials choose a region close to the local DB to ensure the least Network latency. Note Azure databases only use SQL authentication. The username and password doesn’t already have to exists in your azure subscription they will be created for you automatically.
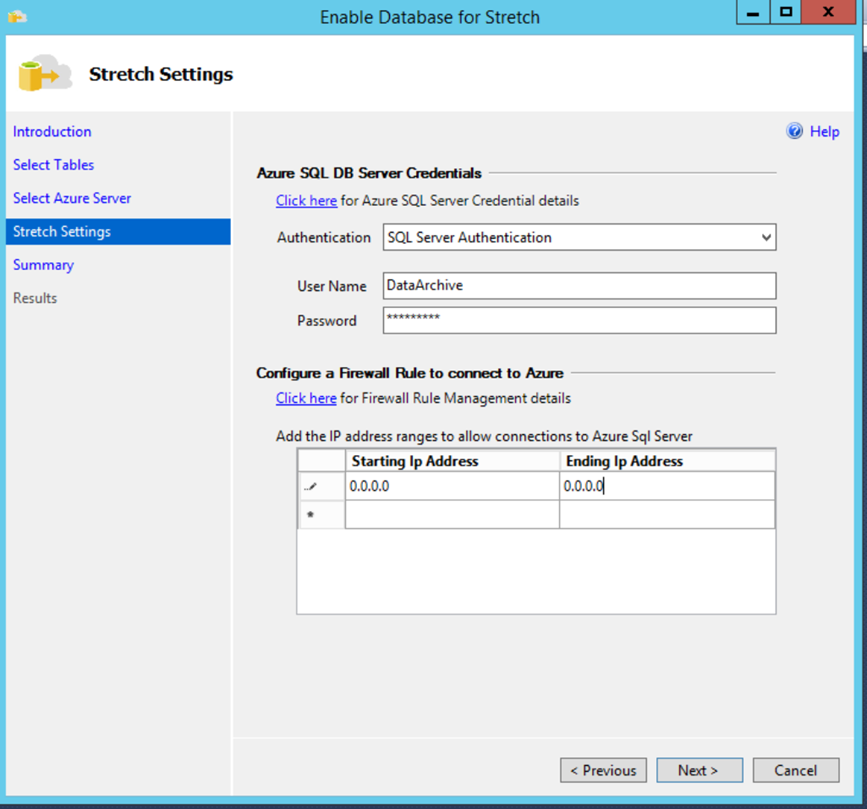
Press Next to reach the summary screen.
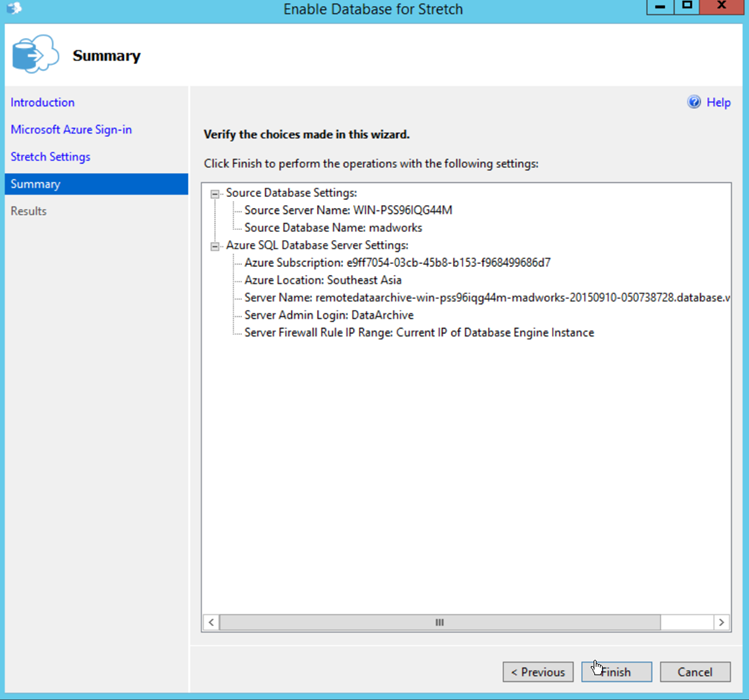
Press Finish to start setting everything up.
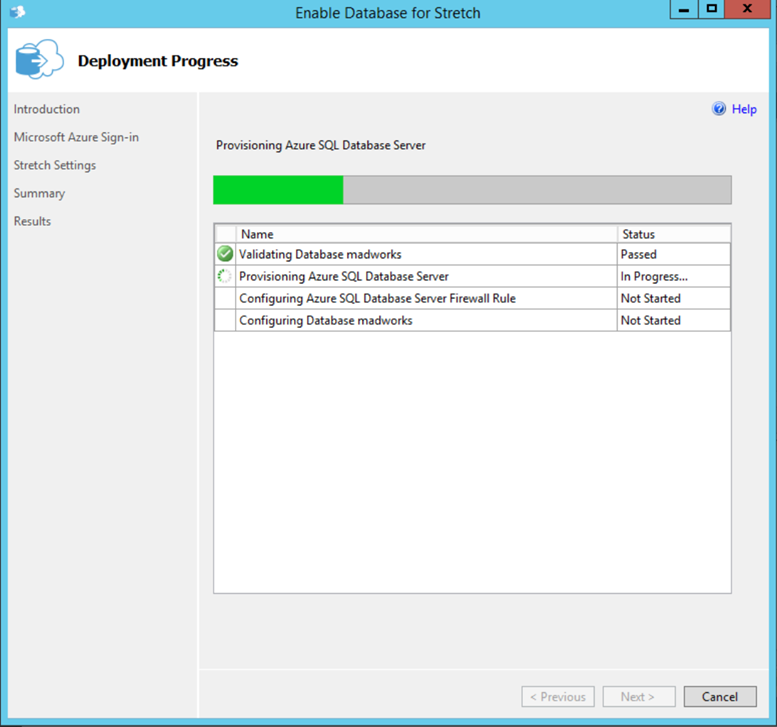
Once completed you should see the below screen.
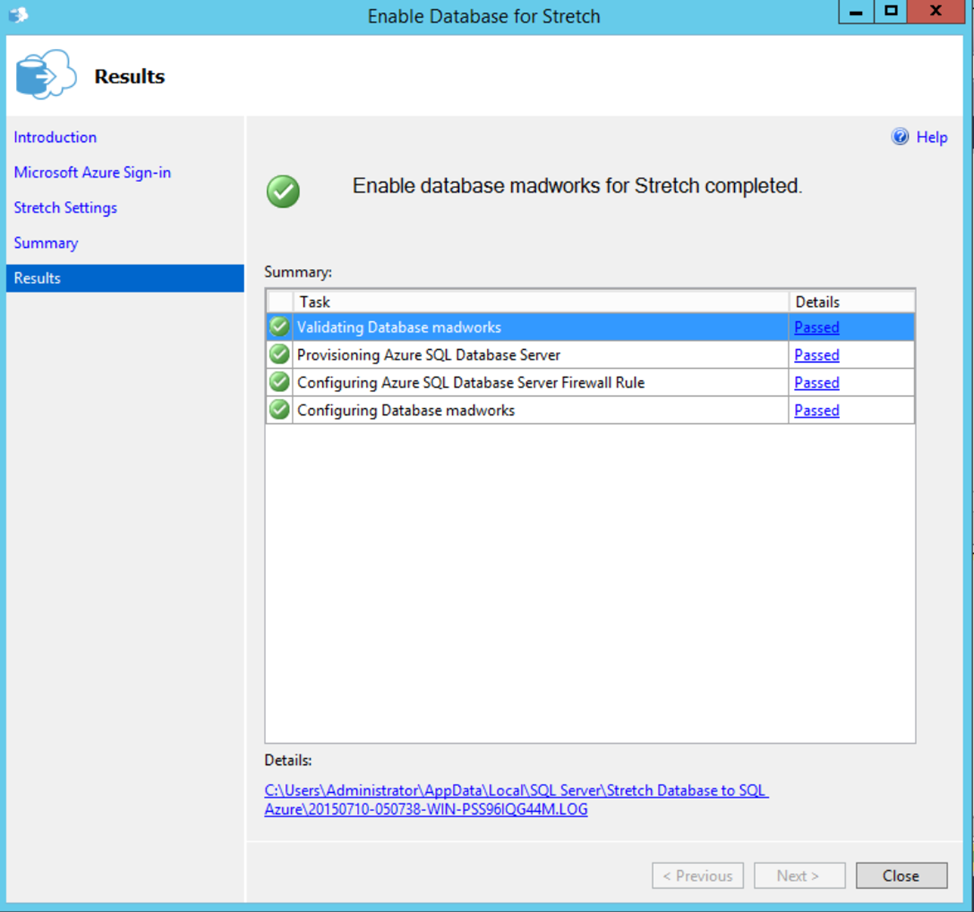
If this step fails with below error message
Sep 15 2015 02:06:03 [Informational] TaskUpdates: Message:Task : ‘Stretch the Database stretchdb’ — Status : ‘Failed’ — Details : ‘Task failed due to following error: Alter failed for Database ‘stretchdb’. ‘.
It is most likely an issue with the firewall and not being able to connect to Azure Server.
If everything goes well and you open the log files you will a new server has been created in the Region
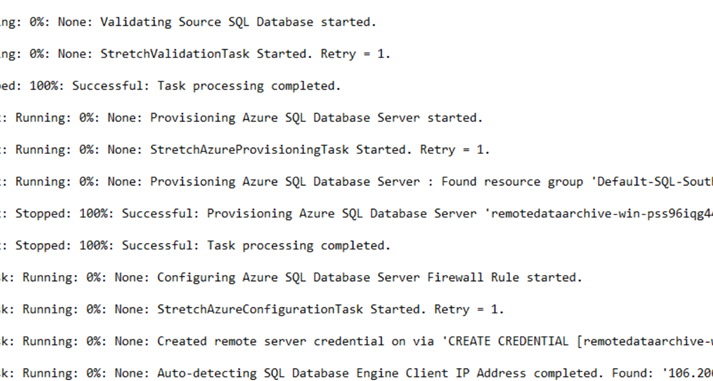
This can be validated by logging into Azure too. You will see that by default the standard Edition is selected with a Storage Size of 250 GB, ( FYI this can be expensive especially when you can use the same server configuration to support a Cloud Availability Group Replica.

You will also notice that a linked server connection is created on the local database which points to the Azure Cloud Database.
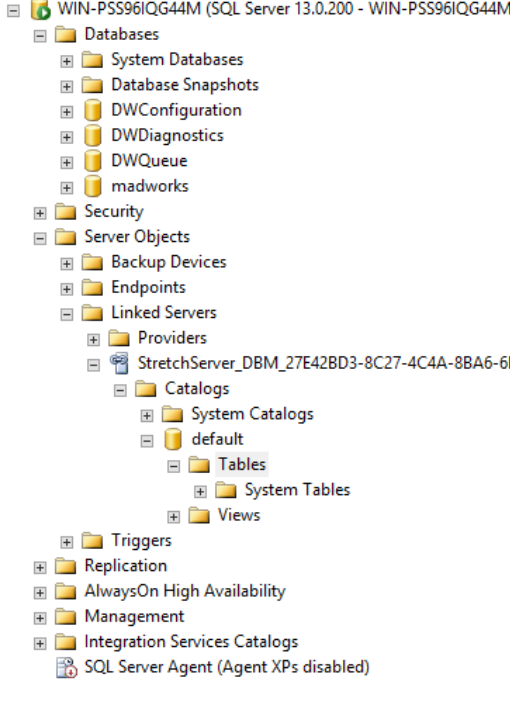
Once configured you can enabled Stretch database on a particulat table by running the below command
ALTER TABLE [dbo].[clientlist] ENABLE REMOTE_DATA_ARCHIVE
WITH (migration_state = ON)Note the syntax is ENABLE REMOTE_DATA_ARCHIVE and NOT ADD as shown in BOL

You will also notice there is no way to limit the rows so essentially you should have an archive table into which the data can be moved from the transactional table before it being moved to the cloud.
remotedataarchive-win-pss96iqg44m-madworks-20150910-050738728
Here is the table as seen when connecting to the cloud database via SSMS
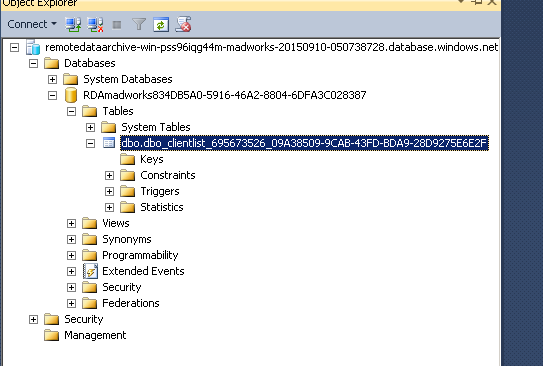
Notice there are no Columns folder. Where executing a query you can tell that there is a remote connection being established by viewing the execution plan.
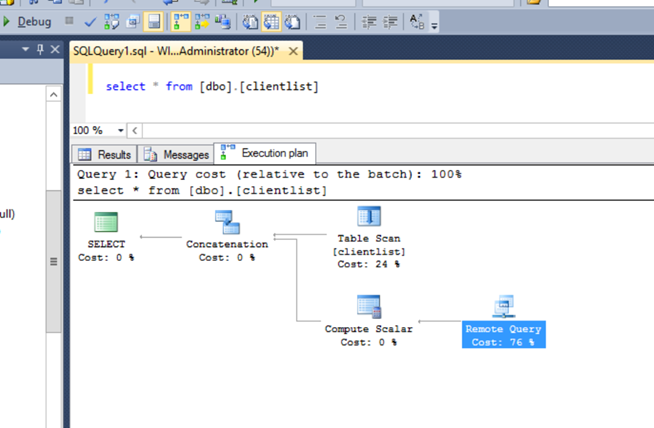
The performance for querying is highly dependent on the network. The tables do not accept default values for columns so most OLTP table are out of the questions here. You can’t create any clustered indexes or constraints either and some datatypes are not supported. FYI I was also not able to create any nonclustered indexes either.
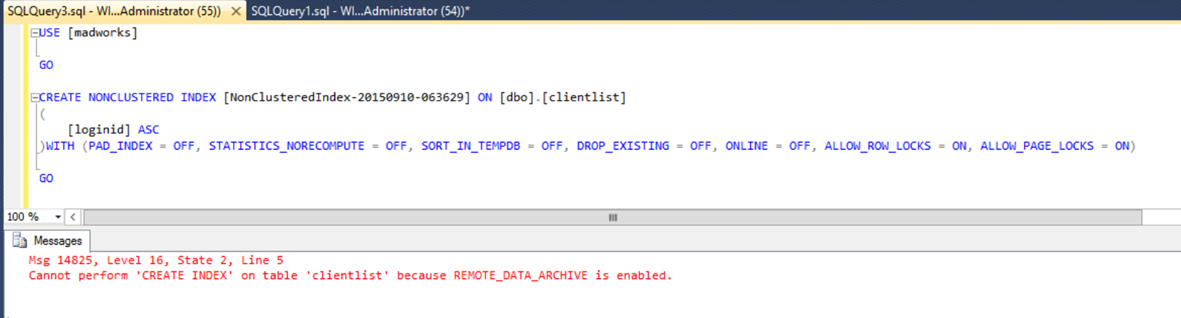
More limitations are mentioned here.
You can query the table directly within the cloud, this also displays the hidden column batchId and could be useful for reporting purposes when used with PowerBI. Note Using PowerBI gateway doesn’t make sense in this case since you still end up fetching the data from the cloud even if the query is initiated locally.
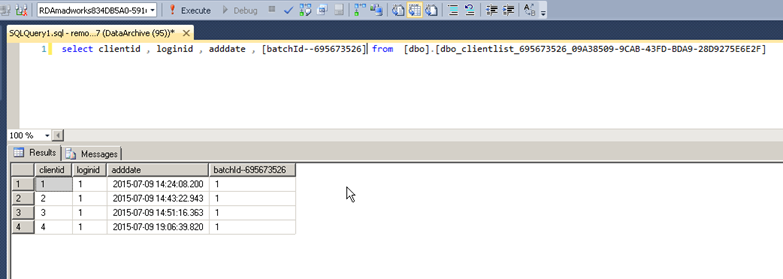
I also tested this feature with the row level security feature introduced in SQL 2016 and row level security is not understood by this feature as a result you will get the below error.
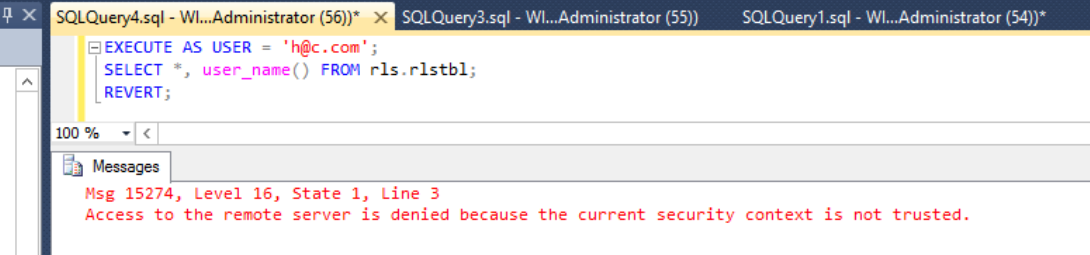
Here is what happens when you try to run insert , update and delete operations , as you can see inserts go thru but update and deletes fail.
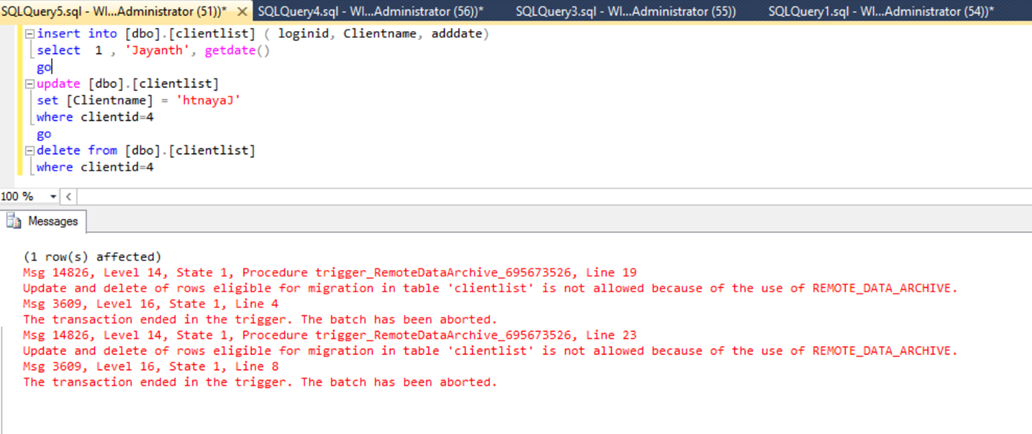
Considering the above a serious question you need to ask yourself is how to move transaction data into an archive table that only allows inserts? Since your only allowed to perform inserts you need to keep in mind that you need an identity column can be used to specify a range or you need an ETL procedure that only uses type 2 SCD else you end up with duplicate records which can mess up the totals. I will most more on this feature soon but initial thoughts makes it feel like a half-baked feature that is not yet production/real world ready.
Please Consider Subscribing
