A named query is a query that is executed in real time to fetch data from the underlying table. In many ways it behaves like a view created in the database. The named query is a layer of abstraction between the cube and the underlying table and while it doesn’t have a variety of options like a table or view it is a critical component to designing a good cube. A lot of the power of the named query comes from the fact that it gives the developer a lot of flexibility when working with the underlying data structures. Let us now look at a few examples where named queries are used frequently.
Masking unwanted columns
As shown in the previous posts when defining the Datasource view entire tables get imported in the Datasource view and therefore all columns within the table are available to the cube. However if there is a requirement that certain columns while being part of the database must not be reflected in the cube or may need to be concatenated in the cube, then rather than create a view in the source database we can replace the table within the Datasource view with a name query.
Let us looks at the credit card table from the adventure works database which we have imported into our Datasource view.
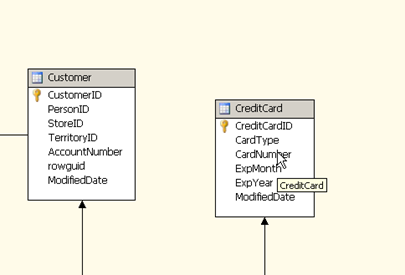
As we can see here the table contains a credit card number column which is sensitive information and not required in order to analyse the sales data. Here it would be good idea to remove this column entirely from the cube data source so that it can never be referenced further downstream. There are options option to make sure the column is not available to users even after creating the Datasource but we should ideally try to start off with just enough information as required instead of fetching everything and then eliminating rows later.
So now let us right click the table and select the option to “Replace table with Named Query”
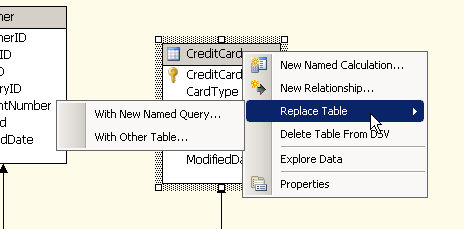
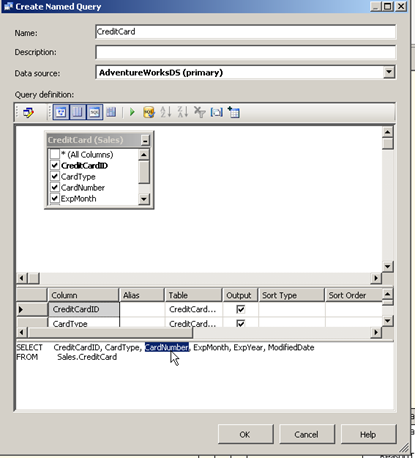
The below screen will appear in which the table is shown along with the select statement used to fetch data from it. Simple remove the unwanted column from the select statement or uncheck the box next to the column name to get rid of the column and Press OK
The data source view windows will no show the table without the credit card number column.
De-normalizing data
Another area where named queries are very useful is in their ability to behave like de-normalized views. For example in the Datasource view that was created for the DemoCube project we imported the orderheader and the orderdetail table. The order header table represents the order number and metadata about the order such as the customer who placed the order etc., the order detail table stores information about what items were ordered and their metadata such a unit price etc. It therefore makes sense that there will not be any order lines without an order header. We can therefore de-normalize the tables into a single named query called order details as shown below.
Right click and select the option to replace table with named query on the Sales order header table. Then in the below windows click the button to add table as shown below and add the table.
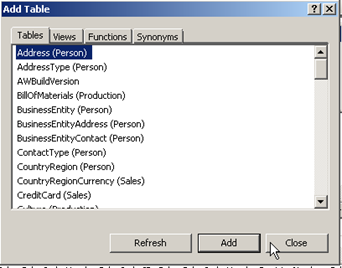
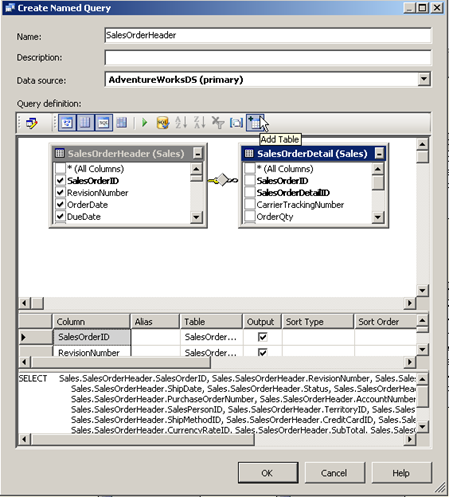
The tables already have a primary key and foreign key relationship which is automatically used to join the tables. Note that the columns from the order detail table are not automatically selected. Select the required columns from the details table and press OK
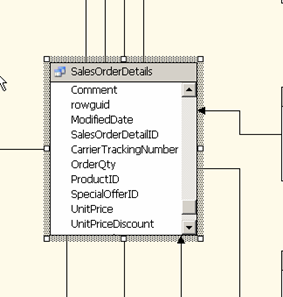
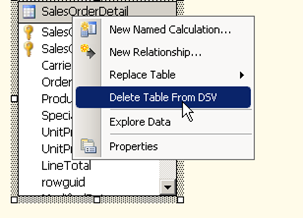
At this point we see the column from sales order details are not reflecting in the SalesOrderDetails named query. We therefore no longer require the original table within the Datasource view. So select that table and press “delete Table from DSV”
In the next post we explore how to add new tables and defined relationships within the DSV when non exist.
Please Consider Subscribing
