I was recently asked if there was any importance of the primary key clustered index in terms of performance. While the answer is obvious I wanted to explore one more option that is not always obvious to most developers. The idea is that the clustered index need not always be part of the primary key. It might be better to explore this option with an actual example so here goes.
Let’s create a set of reference data that can be used to implement something similar to random freetext for example a CustomerEmailID. Typically we would create a customer table and then add an identity column which is the PK and by default has a clustered index. We then proceed to add a non-clustered index on the email id column for queries where we search for customer email id.For obvious reasons we do not use the email ID in our relationships (PK-FK)therefore it never becomes the PK. But does that mean it should not have a clustered index either?
FIRST RUN
CREATE TABLE ##lookups (keyscolumns VARCHAR(128))Staging table for a list of guids( playing the role of randome emailids)
INSERT INTO ##lookups
SELECT newid()
GO 500000Generating the required number of random data
CREATE TABLE IndexKeyColumn (
keys VARCHAR(128) PRIMARY KEY CLUSTERED
,id INT identity(1, 1)
)Table structure where the keys column(playing the role of emailid column is the PK clustered index)
INSERT INTO IndexKeyColumn
SELECT keyscolumns
FROM ##lookups
SELECT *
FROM IndexKeyColumn
WHERE keys = (
SELECT TOP 1 keyscolumns
FROM ##lookups
ORDER BY newid()
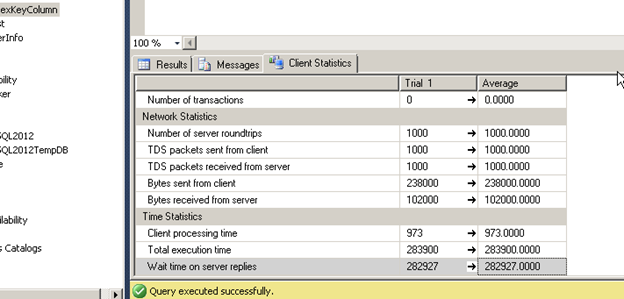
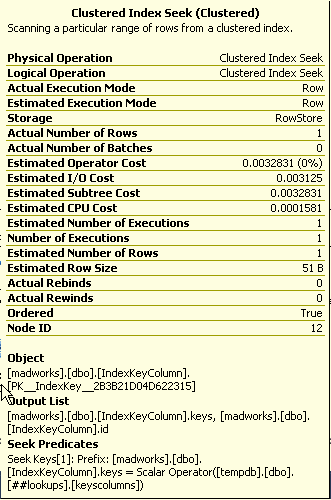
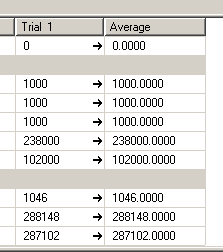
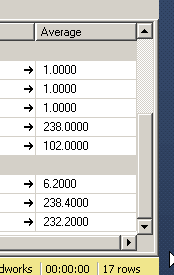
) GO 1000I first created a lookup table and identified a large number of GUID values that could behave similarly to that of emailed. These values were inserted into another table in a column that was a PK clustered index. I executed a query to fetch values from this column randomly and performed 1000 iterations to be sure there was some kind of similarity with a real world scenario.

SECOND RUN
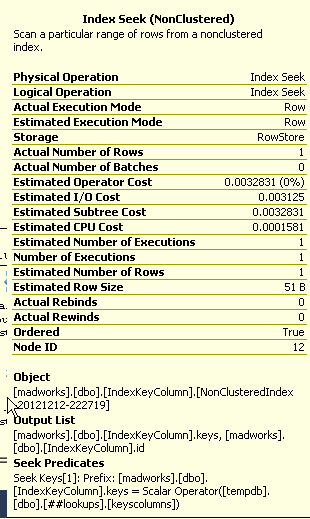
CREATE TABLE IndexKeyColumn (
keys VARCHAR(128)
,id INT identity(1, 1) PRIMARY KEY CLUSTERED
)
/****** Object: Index [NonClusteredIndex-20121212-222719] Script Date: 12/12/2012 10:35:39 PM ******/
CREATE UNIQUE NONCLUSTERED INDEX [NonClusteredIndex-20121212-222719] ON [dbo].[IndexKeyColumn] ( [keys] ASC)
WITH (
PAD_INDEX = OFF
,STATISTICS_NORECOMPUTE = OFF
,SORT_IN_TEMPDB = OFF
,IGNORE_DUP_KEY = OFF
,DROP_EXISTING = OFF
,ONLINE = OFF
,ALLOW_ROW_LOCKS = ON
,ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY]
GO
SELECT *
FROM IndexKeyColumn
WHERE keys = (
SELECT TOP 1 keyscolumns
FROM ##lookups
ORDER BY newid()
) GO 1000As expected the clustered index has the obvious benefit. Since the column which is part of our where condition is the one that has the clustered index it works out well for use when fetching data from a single table. Tomorrow I will explore if this approach has any impact when it comes to joins with other tables.
PS:-The average fragmentation for all indexes in either scenario was less than 5 %. This shouldn’t be a problem since an important table like customer info would be re-built or re organized frequently so fragmentation should always be low enough in either of the cases we are discussing.
Please Consider Subscribing
