Partitioning is a great feature for improving the way we manage our data. However we can also improve performance of select statements from the table as well. This requires a good understanding of the way partitioning works and how properly placing files on the disk can improve the IO performance. One common way that partitioning can improve performance for loading data is the sliding window method but in this post I am mainly talking about how to improve read performance. Before showing the improvements from partitioning it’s important to visit the indexes since a common belief is that a good index can provide faster data access than partitioning can.
You can watch the video here
Does partitioning improve performance?
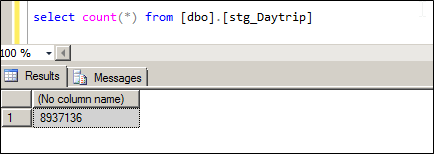
We start off with a table that has 8.9 M rows in it.
The Final results are posted below as a summary to give some context
| Description | Time sec |
| Unpartitioned unindexed table | 22 |
| Unpartitioned unindexed table (MAXDOP=4 , single file) | 22 |
| Partitioned unindexed table (serial) | 24 |
| Partitioned unindexed table ( MAXDOP=4, four files in FG) | 16 |
| Unpartitioned Clustered index Column( serial and parallel) | 28 |
| Unpartitioned Clustered and Non Clustered index Column | 15 |
| Non clustered Columnstore index ( no aggregate, no column elimination, batch mode) | 20 |
BASELINE
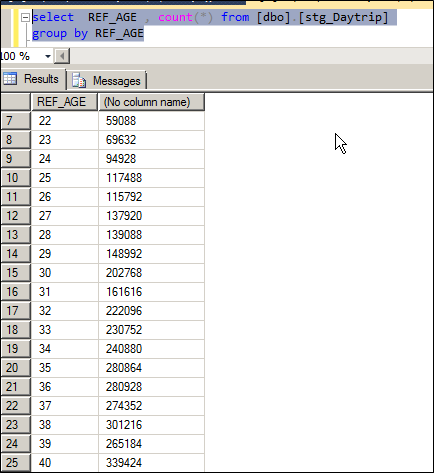
As a benchmark I try fetching data for all customers of a particular age, the distribution of data by age is shown below.
After flushing the buffer pool the time taken to fetch data from the heap is shown below
select *
from [dbo].[stg_Daytrip]
where REF_AGE =30
| SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (202768 row(s) affected) SQL Server Execution Times: CPU time = 3525 ms, elapsed time = 22752 ms. |
So we have a baseline of 17 sec with a table scan as the execution plan.
CLUSTERED INDEX ON PK COLUMNS
Now I create a unique clustered index on the ID column which is an identity column, after rerunning the query the new stats are shown below, this step is unnecessary on its own but included for clarity
| SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 26 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (202768 row(s) affected) SQL Server Execution Times: CPU time = 4181 ms, elapsed time = 28139 ms. |
Not much of a change in fact it’s essentially the same with the table scan replaced with a Clustered index Scan
ADD NON CLUSTERED INDEX ON REF_AGE COLUMN
Next we add a Non Clustered index on the REF_AGE Column to improve the ability seek and filter rows by age. Shouldn’t this prevent the need to do a scan on the entire table?
| SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 5 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (202768 row(s) affected) SQL Server Execution Times: CPU time = 3900 ms, elapsed time = 26736 ms. |
There is not much change, this is important!! The output rows fetched by the above query is 202768, which the optimizer decides is significant enough to not change the execution plan. Now I decide to free the procedure cache and let’s see if we can force a new execution plan to be created. After running the query the execution plan is still the same. The reason for this is
Even after filtering for rows with age 30 SQL still needs to fetch all the remaining columns , this will require an expensive key lookup and wasn’t worth it.
So when it comes to data warehousing just creating the index on the column doesn’t ensure it gets used especially since DW queries unlike OLTP queries end up fetching a significant portion of the data anyway. Now you could argue that no business case will fetch all columns from the table so the index should have included columns. And this would be right for an OLTP system , but in DW systems we design fact tables and all columns in the fact table are used in some query or the other and creating a different set of indexes with different included columns for each scenario is not practical or efficient and degrades Load performance too.
For the sake of completeness I have forced the index to be used with a query hint as shown below
SELECT * FROM [dbo].[stg_Daytrip] WITH (INDEX = [NonClusteredIndex-20151022-130840]) WHERE REF_AGE = '30'
| SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (202768 row(s) affected) SQL Server Execution Times: CPU time = 2652 ms, elapsed time = 15741 ms. |

As you can see after two indexes and query hints we have brought down the execution plan to 15 sec. However imagine how many more indexes will be needed before all reports are done.
ADD A NONCLUSTERED COLUMNSTORE INDEX
So maybe we are using the wrong type of index. With SQL 2012 and above Microsoft have provided us with a special index called the non-clustered and clustered column store index. These indexes provide much better IO and CPU characteristics compared to traditional indexes. Below are the stats provided by the NONCLUSTERED COUMNSTORE INDEX
| SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (202768 row(s) affected) SQL Server Execution Times: CPU time = 20592 ms, elapsed time = 20445 ms. |
Notice how the execution time has increased to 20 sec. This is obviously worse than when we had normal indexes (the mode used for the NCS is batch mode which is the best way to fetch data using this index). So looks like Column store indexes are bad right? WRONG
A single columnstore index can be used to answer any query off the fact table now. So I don’t need to create a large number of indexes on my fact table for all my other reports also I don’t need to include columns which creates additional copies of the data and increases the size of the DW. CS indexes work much faster when the data is being summarized, a common use case for DW queries.
Here I am not summarizing my data therefore there is no benefit from CPU batch mode execution and since I am fetching all the columns from the table there is no columns being eliminated. If I execute the same query with only half the columns in the table the execution time also drops to about half.
Partitioning the table
Now that we know how indexes will affect our query the next step is to create a partitioned table and see the improvements. After dropping all the indexes I create two different file groups, the primary FG now contains only the rows where age is 30 and the rest of the data has been moved to another file. Also the primary filegroup now has 4 files in it.
| SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (202768 row(s) affected) SQL Server Execution Times: CPU time = 3806 ms, elapsed time = 24412 ms. |
After executing the query I see that the performance has degraded to 25 sec, hmm so it looks like partitioning doesn’t improve performance?
But see what happens when I execute the same query this time forcing parallelism and thus using multiple threads.
SELECT * FROM [dbo].stg_Daytrip WHERE REF_AGE = '30' OPTION (MAXDOP 4)
| SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (202768 row(s) affected) SQL Server Execution Times: CPU time = 1809 ms, elapsed time = 16313 ms. |
The execution time came down to 16 seconds, this is the improvement obtained by just placing the data on multiple files. In my case I am using a single SSD drive on which all these files are located , image if there are multiple dedicated DISK LUNs the improvement would be better.
Reference
http://www.sqlservercentral.com/Forums/Topic1729172-3077-1.aspx
Please Consider Subscribing
