
This post talks about a new preview feature being introduced within MS SQL SERVER database engine. Readers are advised to check out the full details in the link below.
Those working in business intelligence solutions often face the issue of cleaning up incorrect data coming from multiple sources. Sometimes this data isn’t even incorrect. It is just a variation of the same word as spelt in a different region. We are more familiar with this when we deal with dates, for example, in some countries, the date format is MMDDYY whereas in other countries it is DDMMYY, etc. But when it comes to words things get a bit more complex.
The word defence is also spelt as defense. Naturally they mean the same thing but it’s not the same when we have to build reports out of this value. Previously, we would use data quality services, SSIS fuzzy lookup ,Soundex etc. identify/fix such issues. However, this works primarily in cases for known values that are part of dimension attributes.
To alleviate this issue for more broader cases such as typos or variations of words in product descriptions etc. we can now leverage the DISTANSE set of function inside TSQL. These include
| Function | Description |
| EDIT_DISTANCE | The number of edits it will take to make the words match e.g. edit distance for the word space and paces is 2 |
| EDIT_DISTANCE_SIMILARITY | A fuzzy lookup score ranging from 1 to 100. useful for cases where the lengths might vary significantly. |
| JARO_WINKLER_DISTANCE | A score based on how similar the starting characters for both strings are. |
| JARO_WINKLER_SIMILARITY | A score range from 0 to 1 |
Edit_Distance and Edit_Distance_Similarity
The below screenshot shows and example of the usage for EDIT_DISTANCE and EDIT_DISTANCE_SIMILARITY, the similarity should be thought of as a fuzzy lookup score ranging from 1 to 100.
-- Check SQL Server version to ensure compatibility with EDIT_DISTANCE functions (SQL Server 2025+)
IF (SELECT CAST(SERVERPROPERTY('ProductVersion') AS VARCHAR(128))) < '16.0'
BEGIN
RAISERROR('This script requires SQL Server 2025 (v16.0) or later.', 16, 1);
RETURN;
END
-- Declare input words
DECLARE @word1 VARCHAR(100) = 'space';
DECLARE @word2 VARCHAR(100) = 'paces';
-- Use CTE to simulate a dataset with the two words
;WITH cte AS (
SELECT @word1 AS W1, @word2 AS W2
)
-- Use SQL Server 2025 fuzzy matching functions
SELECT
W1,
W2,
EDIT_DISTANCE(W1, W2) AS EditDistance, -- Levenshtein distance
EDIT_DISTANCE_SIMILARITY(W1, W2) AS SimilarityScore -- Similarity score (0-100)
FROM cte;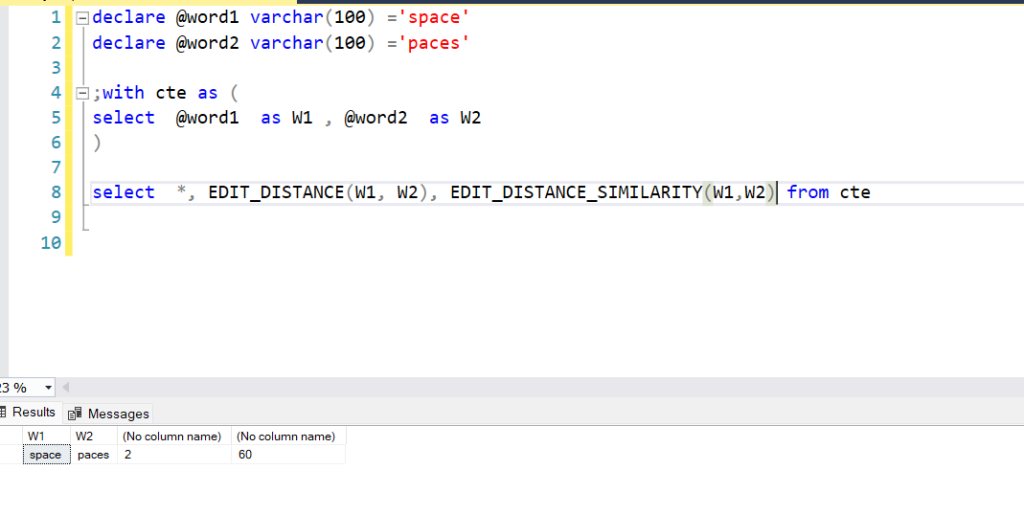
An interesting use case of this function is to differentiate between words that are spelt the same but capitalized. such as the name Green vs the color.
IF (SELECT CAST(SERVERPROPERTY('ProductVersion') AS VARCHAR(128))) < '16.0'
BEGIN
RAISERROR('This script requires SQL Server 2025 (v16.0) or later.', 16, 1);
RETURN;
END
-- Declare two strings to compare
DECLARE @word1 VARCHAR(100) = 'green';
DECLARE @word2 VARCHAR(100) = 'Green';
-- Common Table Expression to simulate a source dataset
;WITH cte AS (
SELECT @word1 AS W1, @word2 AS W2
)
-- Perform fuzzy comparison using SQL Server 2025 functions
SELECT
W1,
W2,
EDIT_DISTANCE(W1, W2) AS EditDistance, -- Levenshtein distance
EDIT_DISTANCE_SIMILARITY(W1, W2) AS SimilarityScore -- Similarity score (0-100)
FROM cte;JARO_WINKLER_DISTANCE and JARO_WINKLER_SIMILARITY
This is a different algorithm to check similarity of words. In the main reason you would want to use it is for words that differ towards the end. For example the words throw and throwing will return poor scores if you use Edit_Distance function but would return a high score using JARO winkler.
IF (SELECT CAST(SERVERPROPERTY('ProductVersion') AS VARCHAR(128))) < '16.0'
BEGIN
RAISERROR('This script requires SQL Server 2025 (v16.0) or later.', 16, 1);
RETURN;
END
-- Declare input words for comparison
DECLARE @word1 VARCHAR(100) = 'throws';
DECLARE @word2 VARCHAR(100) = 'throwing';
-- Use a CTE to simulate a row-based structure
;WITH cte AS (
SELECT @word1 AS W1, @word2 AS W2
)
-- Perform both Levenshtein and Jaro-Winkler comparisons
SELECT
W1,
W2,
EDIT_DISTANCE(W1, W2) AS dist_score, -- Levenshtein distance
EDIT_DISTANCE_SIMILARITY(W1, W2) AS dist_sim, -- Levenshtein similarity (0-100)
JARO_WINKLER_DISTANCE(W1, W2) AS jdist_score, -- Jaro-Winkler distance
JARO_WINKLER_SIMILARITY(W1, W2) AS jdist_sim -- Jaro-Winkler similarity (0-100)
FROM cte;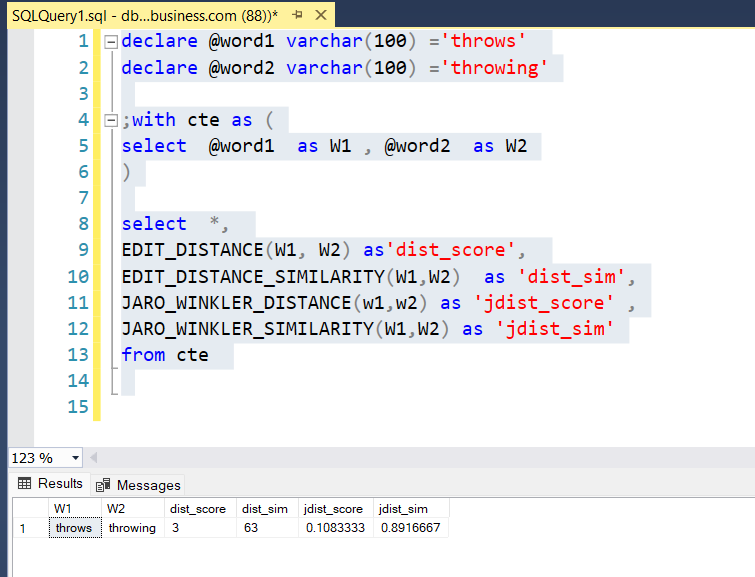
A place I can immediately see a use for this new set of functions is in cleaning up company name like ‘Abcd LLC’ and ‘Abcd’ etc.