When Microsoft introduced Columnstore indexes in SQL server 2012 a key limitation was the table could only be read from and not inserted. While the limitation itself has been overcome in subsequent versions of SQL server we need to understand the impact of how they work to explain performance issues when it comes to accessing table that have Columnstore indexes on them.
First let’s explore the recommended Microsoft solution for situations where you want to do DML operations on table using SQL server 2012. The solution that we typically use was to either drop or recreate index whenever we were loading data. This solution works fine for infrequent data loads such as daily or weekly ETL considering that SQL server Columnstore indexes could be built quickly compared to traditional indexes.
Another solution was to have a historical table on which the Columnstore index should be created for large volumes of data and a current table which would be used to store fresh data in other words a history table and a current table with history table having the Columnstore index and the current table having regular indexes. In order to make the table’s access seamless to the application they were Union’d and referenced via a view
This is very similar to the Delta store approach that Microsoft uses with the clustered Columnstore index for any updatable Columnstore index for that matter. You can think of the Delta store as a hidden internal table (clustered index b tree) into which DML operations are performed so if you insert a row it doesn’t actually enter the Columnstore index instead it enters the Delta store. This Delta store records are then merged with the Columnstore index when any one of the below three conditions are met:
- The tuple mover is executed in regular intervals to merge records from the row store into the Columnstore
- Rebuild of the Columnstore index has been initiated
- The Deltastore has reached maximum capacity of approx. 1M rows.
Another interesting point to consider here is the fact that if you use a bulk insert command and populate over 100,000 rows in the table the segment is automatically stored in a column store compressed format anything less than hundred thousand and it ends up in the Delta store. As you can imagine it might not always be practical to wait until 100,000 rows has been inserted into The Delta store and in order to fix this you really don’t have much of a choice other than start a rebuild yourself or wait for a certain amount of time till the tuple movers next run.
As a quick refresher here are some important numbers with regard to Columnstore indexes.
- 10X – the typical performance improvement/Compression a Columnstore can provide
- 4X- typical performance improvement in batch mode
- 10,000 – Number of rows fetched and sent at a time to query processor in batch mode
- 100,000 – Number of rows that must be inserted in one go using bulk load in order for the data to be stored in Columnstore Mode, less than this and even bulk load is stored in the DeltaStore.
- 1048576 – Number of rows that must be populated into DeltaStore in order for it to be closed and sent of compression in Columnstore index
- 20% – Percentage deleted rows in a Columnstore index to be considered a threshold for rebuilding the index
When the deltastore is full the tuplemover will run at its scheduled interval and result in the rowstore being converted into a Columnstore. You can find the status of the this process by running
select * from sys.dm_db_column_store_row_group_physical_stats

Here I have two rowstores. The second row is in open state because it doesn’t have enough rows in the deltastore to qualify for tuple Mover yet. If data is being loaded frequently you will find multiple rowstores in closed state while they are waiting for their turn with the tuple mover. If the Tuple mover is the reason for the compression then the transition state will say Tuple_mover. If the Index rebuild is the reason for the state change it will say Index_rebuild.
It is possible to have a segment created with less than the 1048576 rows limit mentioned before by simply rebuilding the index. Doing frequent index rebuilds can result in multiple segments that are created but don’t have enough rows in them (it doesn’t work like normal index rebuild where pages are filled based on fill factor). Few number of rows per segment might be better for segment elimination while a query is being executed but it is also compressed less optimally.
There are few events that capture Tuple Mover execution as shown below
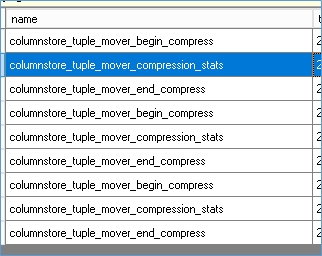
As you can see they don’t always finish the task instantly and as a result tuple mover might lag behind the data load process resulting in poor performance on Columnstore tables for larger durations.
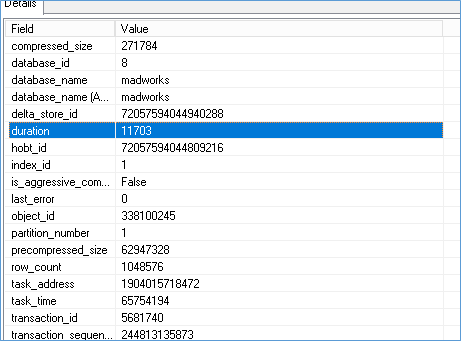
You can disable tuple mover by running TF 634 but this disables tuple mover for entire server. I don’t recommend it because for most cases Tuple Mover works well. Running this TF make you rely solely on index rebuilds and I find that process to be highly unstable in most processes.
Here are a list of DMVs you want to monitor for Columnstore indexes.
SELECT *
FROM sys.dm_db_column_store_row_group_operational_stats
SELECT *
FROM sys.dm_db_column_store_row_group_physical_stats
SELECT *
FROM sys.column_store_dictionaries
SELECT *
FROM sys.column_store_row_groups
SELECT *
FROM sys.column_store_segments
Please Consider Subscribing
