One of the features being released in SQL 2019 that has got some attention is table variable deferred compilation. As its name suggests it applies to Table Variables and not temp tables, CTEs, or table datatypes. More importantly why does it need to do deferred complication for Table variables?
One of the drawbacks of Table variables is that to do no have an accurate row count before the query execution and as a result their estimated row counts was always 1. As you may be aware from previous blogs and video on this site, this results in a number of situations where memory grants and execution plans are sub optimal. By delaying the compilation of a sub plan that references a table variable SQL Server gets a chance to capture the correct row count within the table variable and as a result improve the execution plan for downstream operators.
Before we can see how this look in SQL 2019 it is a good idea to see how it used to be on SQL 2016.
The below query is executed on the exact same dataset in SQL 2016 and SQL 2019
DECLARE @tablevariable TABLE (customerid INT)
INSERT INTO @tablevariable
SELECT customerid
FROM customers
WHERE IsMember = 1
SELECT customerid
,password
FROM Customers
WHERE customerid IN (
SELECT customerid
FROM @tablevariable
)
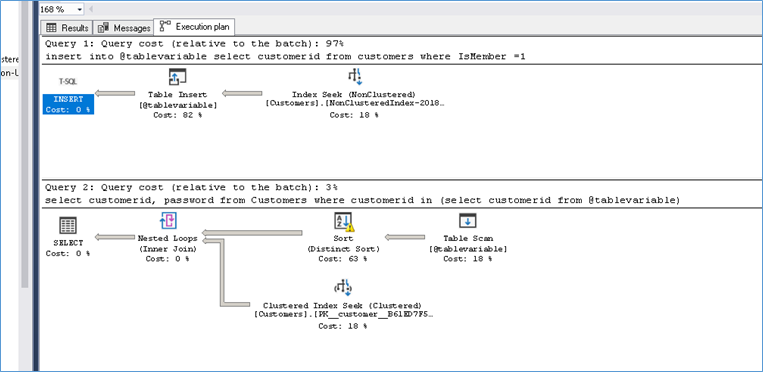
Here is the execution plan from SQL 2016
Here is the execution plan from SQL 2019
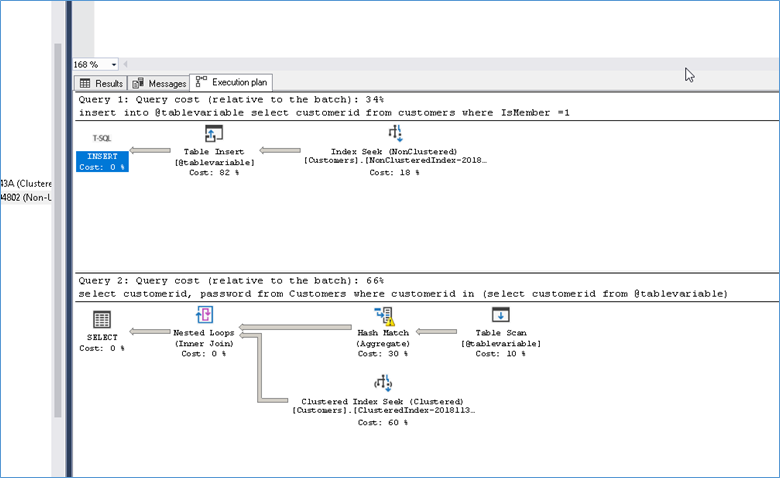
Notice how the Sort operation from SQL 2016 has turned into a Hash Match Aggregate in SQL 2019.
Here are at the execution plan details for the table variable from both SQL 2016 and SQL 2019 side by side
SQL 2016 | SQL 2019 |
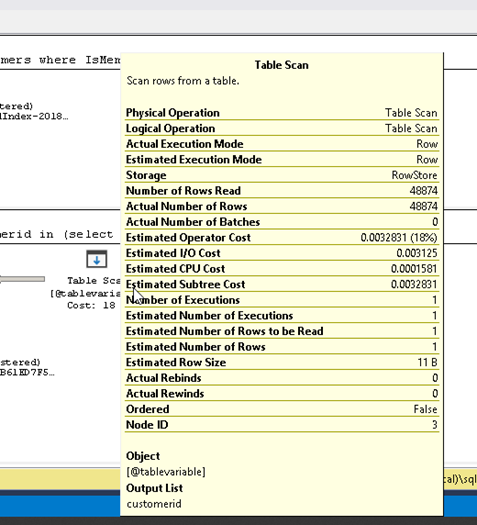 |  |
See how the former has an Estimated Number of Rows to be read as 1 and the actual as 48874 while the later has the same number of rows for estimated as well as actual. So what does this mean for performance?
Here is the output from Set Statistics time, IO on for SQL 2016

Here is the output for SQL 2019
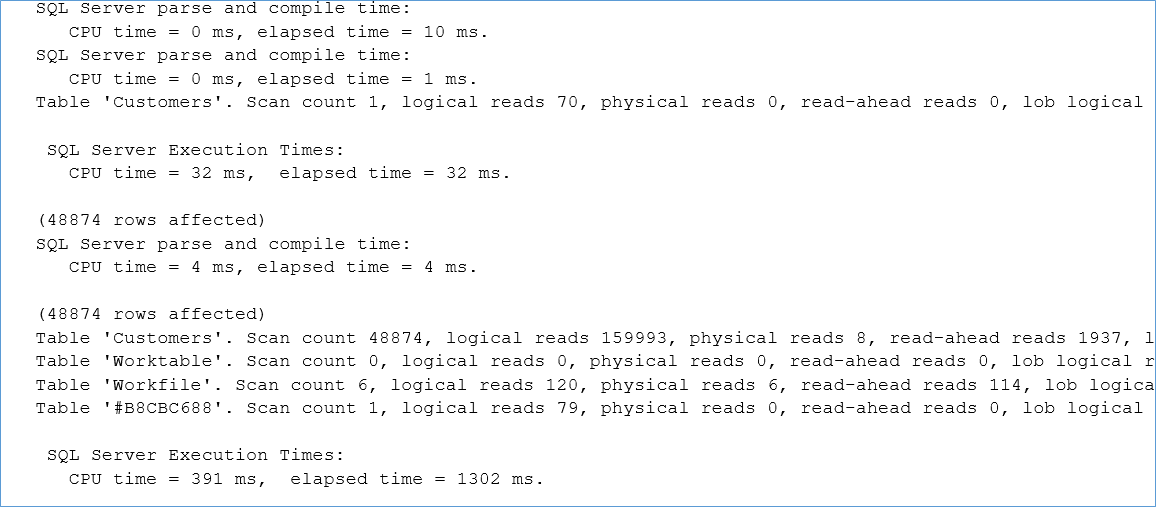
Naturally we can see that the performance has increased from 2800 ms to 1302 ms but more interestingly the Query Compile time for the latter is less compared to the former even though it is a deferred compile.
So overall this features does improve query performance but it still raises the question if we had an accurate row count now why did we still get tempdb spill warnings as can be seen from the execution plans earlier.
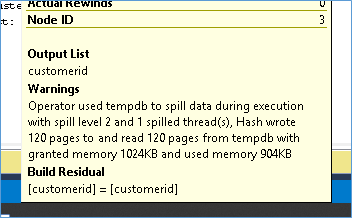
Shouldn’t a more accurate row count has resulted in the correct amount of memory being granted and more importantly why didn’t intelligent Query processing detect and correct the issue in subsequent runs? More on this in the next blog.
Please Consider Subscribing
