We saw this coming with the demand for highly transaction database becoming more frequent clubbed with the need to store data in very large sets. Naturally one precludes the other. BI required more data to be collected and stored which resulted in performance of queries to reduce since the base table got larger without any real improvements to the way the developer wrote code or changes to the optimizer to find better execution plans.
In memory OLTP is a shortcut that allows you to now store datasets in RAM while still following ACID principals. The advantages are tremendous. We see that every system has a few core transactional tables or reference tables that are used the most. By putting these tables in RAM we take advantage of
- Better IO since RAM has always been faster than IO
- Better use of the way SQL has always handled RAM, the more the better.
- Since In Memory OLTP doesn’t use the traditional PAGE approach there are fewer concurrency issues.
- Access to RAM based structures especially since they no longer use PAGE algorithms meant there needed to be a new way to arrive at the execution tree for procedures. This is generally faster.
There is a lot to cover on this topic so today we are going to stick to just how to implement it. It is important to note that the name is In Memory OLTP, what this means is that for OLAP system you would still end up using ColumnStore indexes (which are now updatable).
In order to implement In Memory OLTP one of the first things you need to do is create an In-Memory file group. This can be done via the UI or T-SQL.
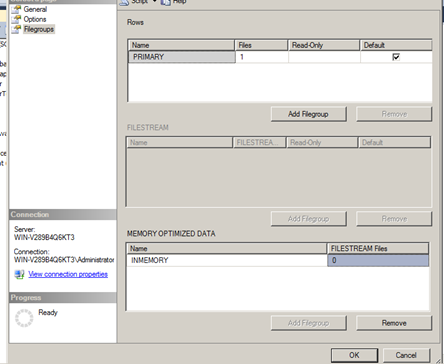
Please keep in mind that In-Memory OLTP requirements are in addition to normal RAM requirements the server has for regular operations and tables that do not reside in RAM. Plan accordingly. Also once a File group is created for Memory optimized data you cannot get rid of it without dropping the database.
If you have a table that you want to move into the RAM, you should right click the Table in SSMS and run the Memory Optimize Advisor. MSDN recommends that the amount of RAM and disk space allocated should be double to the size of the table being used. Mainly to account for versioning.
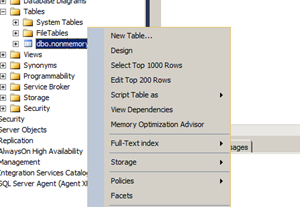
It runs a number of checks in order to determine if the table meets the criteria to become an In memory table
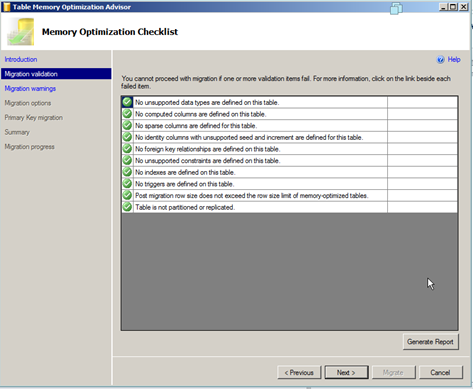
Please read the above list is to understand what the restrictions are on the table. Right off the bat you will see that a lot of table in normal usage cases become ineligible. You cannot have compute columns; the table cannot be partitioned or replicated. Default constraints are not allowed.
The next screen shows a list of additional T-SQL Commands and operations that won’t work with In Memory tables. For a complete list click here.
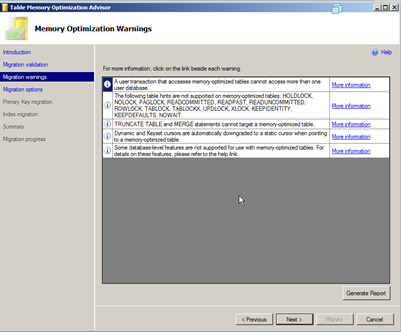
In the next screen we are asked for some input
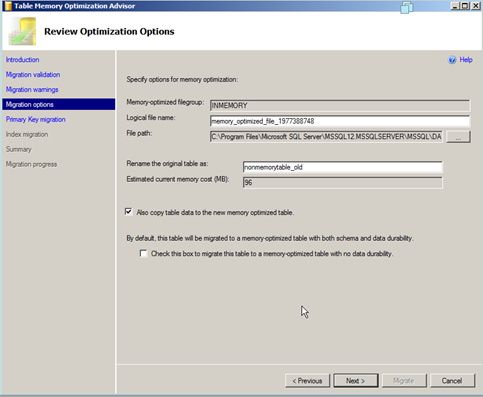
All the above inputs are self-explanatory except the last one. So let’s talk about it. As you know RAM is volatile which means that it can lose data in the event of a power failure. With IN Memory OLTP we now have ACID principles in effect for both the schema and data , what this means is that the tables stored in the RAM can be made durable for both the table schema as well as the data contained in it or only for the table and not for the data, This is akin to creating a temp workspace in the RAM and would be an excellent way to load staging tables in ETL processes going forward.
By checking the last box you’re effectively telling SQL not to worry about the data.
In the next screen we discuss the way the table would use indexes. As you can see there is a need to create a primary key which should not be that difficult since most tables have one. What matters more here is the type of non-clustered index structure used for the primary key (Primary Key does not always mean clustered index). E.g. you can use a traditional non clustered index if you have one; the traditional NC index works better for range lookups. When you want point lookups (very similar to key lookup) you would need to create a Non Clustered Hash Index which expected a bucket count. The bucket count needs to be calculated by the DBA and we will cover this in detail in a later post. For now we are going ahead with a traditional index first.
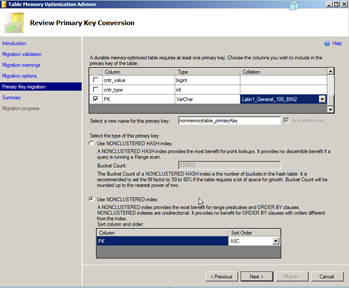
Once the requirement for PK is completed the next option you may get is to migrate the existing NC indexes into the new Hash format. For now we leave it as it is. Quick note about indexes in In-Memory tables is the collation plays an important part in whether the index is allowed or not.
The rest of the screens are just summary and progress information
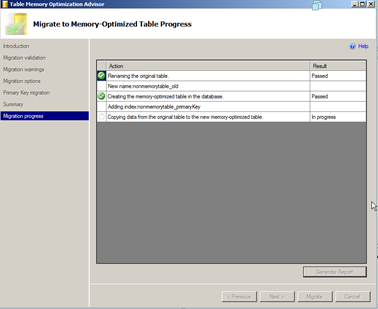
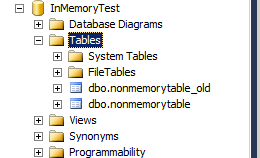
When it’s done you will see the new table in Object explorer in SSMS
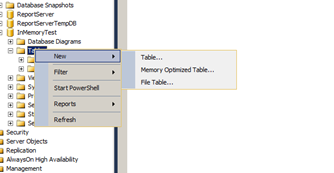
Once the database is created you can create an In Memory table simply by right clicking the table folder, most of the options for the create table syntax have already been explain above.
In the next post we are going to do a quick comparison of the performance of this table as File based and In Memory based.
Please Consider Subscribing
