Recently I had to employ functions to perform a kind of name resolution on a column within the database. The database had a user table with usr_name and usr_id and then all other FK tables used usr_id . Within the procedures we could naturally do joins to fetch the username but there were many other tables similar to Users table. So we would end up having to do many different joins every time on each procedure where additional details were required.
The point here is that we had to use functions since it made a lot of sense, instead of doing joins with 8 different tables to fetch 8 different types of names. However this also posed the problem of having to work with code that was inherently inefficient. I have always asked developers to avoid using functions where possible to help improve performance but this time we needed ease of coding along with decent performance. As far as options go we could use scalar values functions or table values functions. The very nature of these two types of functions is different. As its name suggest a scalar function returns only one value, i.e. one input one output usually this works for performing calculations like service tax etc. Table values functions on the other returns a table. Best used for things like fetching a list of addresses when a zip code is passed or something like that. Naturally in my scenario in terms of pure logic of operations a scalar function is what is needed. It will accept a usr_id and return the fullname of the user but scalar functions are extremely slow and gets worse as the number of rows in the base table increases. Here is the performance comparison for the same.
SELECT *
FROM fk_table f
LEFT OUTER JOIN pk_users u ON u.usr_id = f.usr_id

The above numbers are after three runs with clustered index on tranid and usr_id.
Now we create a scalar function to fetch the data.
SELECT *
FROM fk_table f
LEFT OUTER JOIN pk_users u ON u.usr_id = f.usr_id
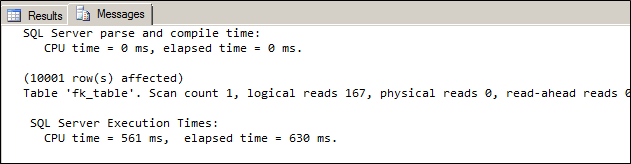
As you can see from the above screenshot scalar functions to bring a significant performance overhead , so we are now going to replace the same logic with a inline table valued function.
SELECT *
FROM fk_table u
OUTER APPLY fn_tblusername(u.usr_id) f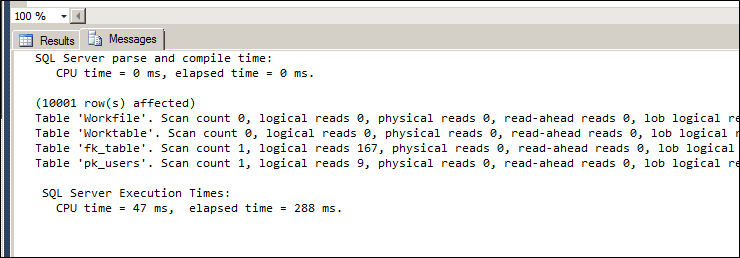
So as you can see from the above screenshots replacing with the table valued function gave me comparable performance as using an inline query without the row by row overhead of a scalar function. Which ultimately serves the purpose of being easy to reuse my code as well as get an acceptable level of performance.
Additional references
/***************************************************************
FILE: Codeformat.sql
DESCRIPTION:
This script demonstrates the creation and usage of tables,
test data, and user-defined functions in SQL Server.
CONTENTS:
1. Table Definitions:
- pk_users: Stores user information with an identity primary key.
- fk_table: Stores transaction data referencing users.
2. Test Data Insertion:
- Inserts 1000 random users into pk_users.
- Inserts 10,000 random transactions into fk_table.
3. Query Performance Statistics:
- Enables STATISTICS TIME and IO for performance analysis.
- Performs a LEFT OUTER JOIN between fk_table and pk_users.
4. Scalar Function:
- fn_getusername: Returns the user name for a given user ID.
5. Table-Valued Function:
- fn_tblusername: Returns a table with the user name for a given user ID.
6. Example Queries:
- Uses the scalar and table-valued functions to retrieve user names
associated with transactions.
USAGE:
Execute this script in SQL Server Management Studio (SSMS) or a compatible
SQL Server environment to create the schema, populate test data, and
experiment with user-defined functions and query performance.
NOTE:
- The script uses the GO batch separator, which is supported in SSMS.
- Test data uses random values and may not represent real-world scenarios.
***************************************************************/
/****** CREATE THE REQUIRED TABLES ******/
CREATE TABLE pk_users (
usr_id INT identity(1, 1)
,usr_name VARCHAR(100)
) GO
CREATE TABLE fk_table (
tranid INT
,usr_id INT
,somedate DATETIME
,sometext VARCHAR(100)
) GO /****** INSERT TEST DATA ******/
INSERT INTO pk_users
SELECT cast(newid() AS VARCHAR(100)) GO 1000
INSERT INTO fk_table
SELECT round(rand() * 10000, 0)
,round(rand() * 10000, 0)
,getdate()
,replicate('a', 100) GO 10000 /****** CAPTURE STATISTICS ******/
SET STATISTICS TIME ON
SET STATISTICS IO ON
SELECT *
FROM fk_table f
LEFT OUTER JOIN pk_users u ON u.usr_id = f.usr_id GO /****** CREATE SCALAR FUNCTIONS ******/
CREATE FUNCTION fn_getusername (@usr_id INT)
RETURNS VARCHAR(100)
AS
BEGIN
DECLARE @usr_name VARCHAR(100)
SELECT @usr_name = usr_name
FROM pk_users
WHERE usr_id = @usr_id
RETURN @usr_name
END GO
SELECT dbo.fn_getusername(f.usr_id)
,f.*
FROM fk_table f GO /****** CREATE TABLE VALUED FUNCTIONS ******/
CREATE FUNCTION fn_tblusername (@usr_id INT)
RETURNS TABLE
AS
RETURN (
SELECT usr_name
FROM pk_users
WHERE usr_id = @usr_id
) GO
SELECT *
FROM fk_table u
OUTER APPLY fn_tblusername(u.usr_id) f
Please Consider Subscribing
