Recently someone posted a question on one of the popular groups on Linkedin about one of the most fundamental structures in RDBMS the PK. It was followed by a number of comments and while all the comments were essentially saying the same old things we all know about the PK , it wasn’t being said well ( in my opinion) so here I try so discuss some fundamental things everybody should know about the PK or Primary Key.
Before we get into the Primary key let’s just talk about the meaning of the word Key.
Ok, so what is a key column?
In its essence the key means column(s) with a unique combination of value that can be used to identify a row(s) within a table.
If a key has more than one column it’s called a composite key for example you can have composite primary key which is a PK with more than 1 column.
What if I have two columns either of which can be used to identify rows within a table?
Then the correct term would be you have two candidate key columns either of which independently can be used to identify the rows.
How it that different from a business/natural key?
A business/natural key is a column(s) that your business understands or uses to identify a row within the table e.g. customers may register on a site using their email ids and the business can identify a customer by looking up their email id, however it might not be the best column to use throughout your system since business may choose use the email id differently or they might need to be encrypted etc.
Instead you create an artificial key column that helps isolate the business process from the internals of the database design. This artificial key is called a surrogate key.
So how it this applied for Primary Keys vs foreign keys?
The difference between a Primary key is that the unique combination of values from the key columns can identify only one row in the table while in a foreign key it may point to one or more rows. In addition a FK would only accept values that are already present as part of a PK (or UNQ Constraint) on some other table.
Ahhh, but your forgot to mention that a PK also has a Clustered index on it
No, I didn’t. You don’t have to have a clustered index on a PK Column(s). Checkout the screenshot below, the clustered index is created on the names column but the PK is the ID column also notice that is uses a Unique NonClustered index now.
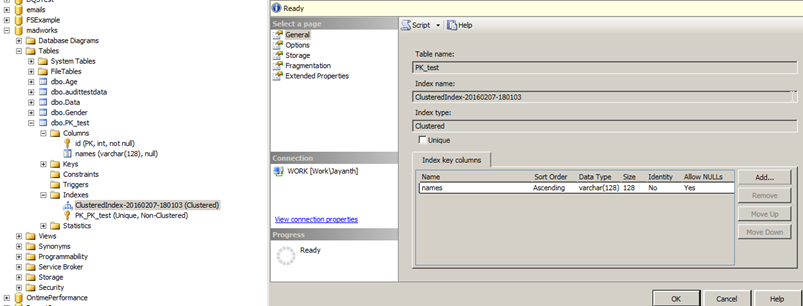
So you’re saying we can use a Unique Non Clustered Index to establish referential integrity between tables?
Yes, Tables can be related to each other without having to use an actual Primary key. See the screenshot below, notice that the database Diagram support popups say Primary OR Unique Constraint
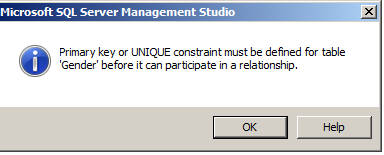
But surely it’s got be unique and NOT NULL?
Yes, it has to be unique, e.g. if you have two columns then the values from Col A when combined with the value for Col B should be unique across all rows in the table and the columns cannot accept any NULL values.
Is that it?
Just one more thing, a table can have only one PK, why? It is defined as per ANSI standards that’s all. So it’s not related to the fact that a table can have only one clustered index? Not really, ANSI doesn’t make any recommendation with regards to indexes.
So should every table have a PK?
If you have followed normalization ideally the combination of all the columns within the table would be unique, however it would be a lot easier to refer to just one column than the entire set every time you want to check. It would help simplify validation, joins and lot of internal business logic as well.
Is there any drawback to creating a PK on every table?
Size used by the PK can be a problem for very large tables if the column has not been selected properly. Once implemented it’s very difficult to undo problems with incorrect selection of PK since the columns will be used in many joins and where conditions within the system. Because of the default behavior of creating a Clustered index on the PK Columns there is an IO impact as well if not selected properly.
If am only looking for referential integrity should I bother with PK when I can achieve the same using a UNQ Constraint?
While the end result of either would be similar in most cases you need to keep in mind that the UNQ Constraint allows a single NULL and is implemented using a Non Clustered index which has size and IO implications. So if your data allows it and you have accounted for things like index fragmentation etc. still consider using a PK before a UNIQUE Constraint J
Please Consider Subscribing
