While working at Thomson Reuters I was part of the Search and navigation team and we had a number of reports created around the data being analyzed from the FAST search engine. The problem with analyzing the data was that the search phrase was often very long since it included the actual user string as well as system generated context information as well. Now the actual search string while not aggregated was still a Fact that was important but it was too long and occupied far too much space within the database tables. Typically a query phrase column would be 500 bytes on average, and for millions of queries being generated every day you can see how this is a problem. At the time we solved this problem by compressing the query phrase as part of the ETL process using .Net but with SQL 2016 we now are able to store data in compressed format directly using TSQL.
The COMPRESS command takes an input string and compresses it using Gzip algorithm into a binary representation.
The following datatypes are currently supported and since it covers some of the most frequently used datatypes I think we should be OK.
nvarchar(n), nvarchar(max), varchar(n), varchar(max), varbinary(n), varbinary(max), char(n), nchar(n), or binary(n)
I noticed that the space savings is proportional to the number of duplicates in the data, i.e. if the input string is highly unique the compression is still effective but not as great as you would expect. You will also see from the below screenshot that sometimes using compression isn’t saving space at all, e.g. in the first result set from the below screenshot the actual length of the string is 38 but the compressed varbinary output datalength is 58 bytes. You will also see that the compression algorithm does take into account leading and training spaces unlike the normal varchar nvarchar datatypes so a lot of spaces in your text isn’t going to ignored like it would normally.
DECLARE @datasize VARCHAR(max) = 'While working at TR I was part of the.'
SELECT datalength(compress(@datasize)) AS SizeOfcompressedString
,LEN(@datasize) AS LengthofString
GO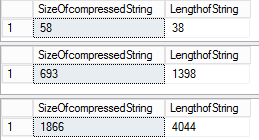
The below table compares the compression benefits of Clustered ColumnStoreIndex, Page Compression , Heap and TSQL Compress statement ,in that order.

As you can see the ColumnStore index provides the best compression followed by the compress command and then Page level compression. The level of compression will depend on the data but it’s pretty obvious that the CS wins by a mile.
Here is the T-SQL used for the above chart
CREATE TABLE TestTbl_compress (
id INT
,textdata VARCHAR(1000)
)
GO
-- Simulating random data with duplicates within the row and across columns
INSERT INTO TestTbl_compress
SELECT 1
,replicate(cast(newid() AS VARCHAR(50)), rand() * 5) GO 10000
-- Creating different versions of the test table , one for Clustered CS , one for Page Compression and one for T-SQL Compress Command
SELECT id
,Compress(textdata) AS textdata
INTO TSQLCompress_tbl
FROM TestTbl_compress
-- DECOMPRESSING THE Compressed String
SELECT Cast(DECOMPRESS(textdata) AS VARCHAR(1000))
FROM TSQLCompress_tblSearching on a compressed string is resource intensive as shown below
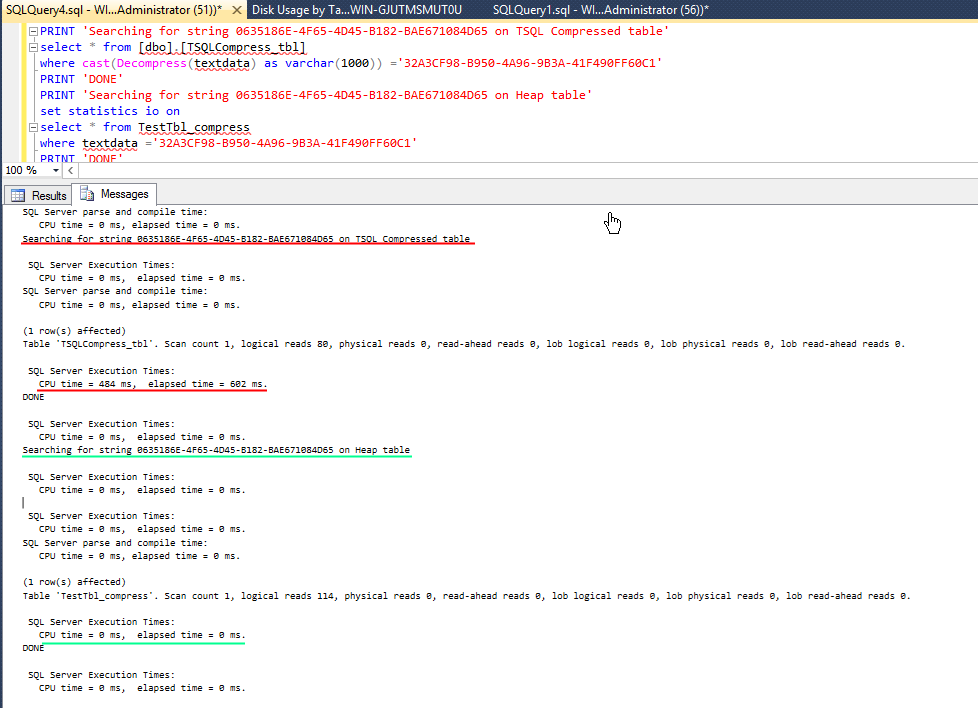
So when should you use the Compress function within T-SQL?
- When archiving data permanently such that it won’t be queried again
- When storing resumes or large word documents that do not need to be Full text indexed ( image files do not offer any significant compression and probably better off in File stream)
Simply put I would use the Compress feature when the data being queried is
- larger than 800 bytes ( just my own number)
- not frequently searched based on the compressed column
- contains a lot of redundancy within the data
- clustered columnstore index is not an option.
Please Consider Subscribing
