A key part of every DBAs jobs is maintaining uptime. A DBAs capability is measured by the amount of Uptime he is able to ensure on servers he manages. An important part of this is calculating the uptime of the servers. While it might sound simple over the years I have seen different calculations being used to derive the uptime for a server.
In its simplest term uptime is calculated as the total time the server has been running over a particular duration. So if the defined time period is 1 year the calculation goes as shown below:-
Count the number of minutes in the year = Total Time = 525600 Count the number of minutes the server was down for the said year= 5.26 Calculate the uptime in nines format (1- (Downtime/Total Time)) = 1- (5.26/525600) = 99.9990% |
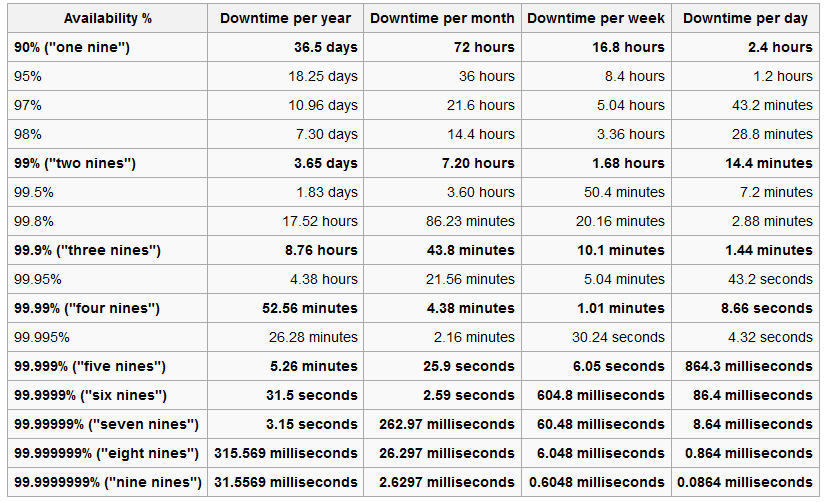
However depending on where you work the definition of “down time” differs. For example a hosting provider doesn’t see it as downtime when the server is offline during non-business hours. Also the same amount of downtime might indicate different number of nines if measured over a leap year. Planned deployments are generally not accounted for under downtime since downtime implies unexpected shutdown. Sometimes the server doesn’t have to be down it simply needs to be unresponsive. If the server is unresponsive it doesn’t get counted under downtime since technically the server is still up, however the end user sees it as down, also its more difficult to measure unresponsiveness. Similarly network downtime doesn’t count as DB down time even if the DB is unavailable since there is nothing to fix on the database side.
Most often the DBA measures only the database uptime, if a server fails the down time of the server might be significantly higher compared to the database downtime e.g. when using clustering or mirroring.
While to concept of 5 nines is good to hear from a business stand point, the true measure of Server and Infrastructure health is “Mean time between failures”, a term the airline industry is very familiar with. The mean time between failures as its name suggests is the time duration between failures, put another way it’s the frequency with which errors happen on the system. How is this a true metric?
To achieve 4 nines you have a window of 52 min a year. This means you can have 1 failure of 52 minutes or 10 failures of 5.2 minutes each. This means in best case scenario the MTBF is either 1 year or in the worst case its once a month. Considering the above information would you still feel safe deploying mission critical databases to the latter? A drawback of the MTBF is that it doesn’t measure the duration or the impact of the failure, this means you can have a failure that lasted 2 days and then not have any other failures for the rest of the year and still end up with a number that looks really good. A combination of the two would provide a more complete picture on how frequently and how badly a server is affected by outages.
So the next time you decide to go with a hosting or cloud provider find out the much advertised Nines and the MBF before taking a call.
Please Consider Subscribing
