At a training recently we were talking about improving ETL performance for a process that loads about 3 million rows. While the answer is typically to load the data after dropping the indexes, in this case they wanted to load the data with indexes since the data would then be needed to perform looks up for downstream processes. The cost of rebuilding the index would out weight any benefit derived from removing it during the ETL so we had a slightly difficult situation to cover. The lookups required referential integrity and therefore the primary key was created with a clustered index. However I suggested getting rid of the clustered index in favor of the unique non clustered index, here is why
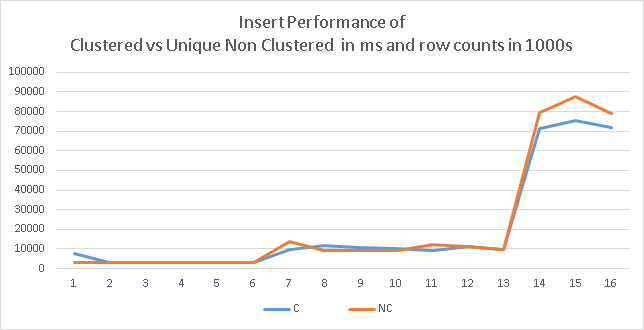
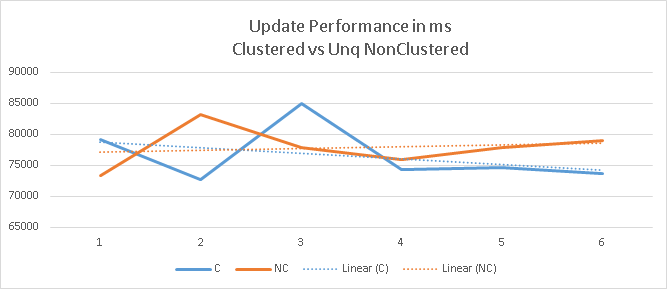
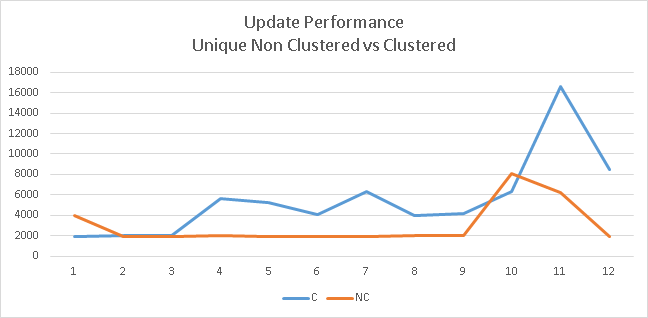
From the above two charts it seems there is not significant benefit to be gained from unique Nonclustered index while performing Inserts and Updates. However when you look at the below chart you will see that Unique non clustered index provides significant benefits during updates if columns being updated is one of the key columns.
Please Consider Subscribing
